SCOUT+: Towards Practical Task-Driven Drivers' Gaze Prediction
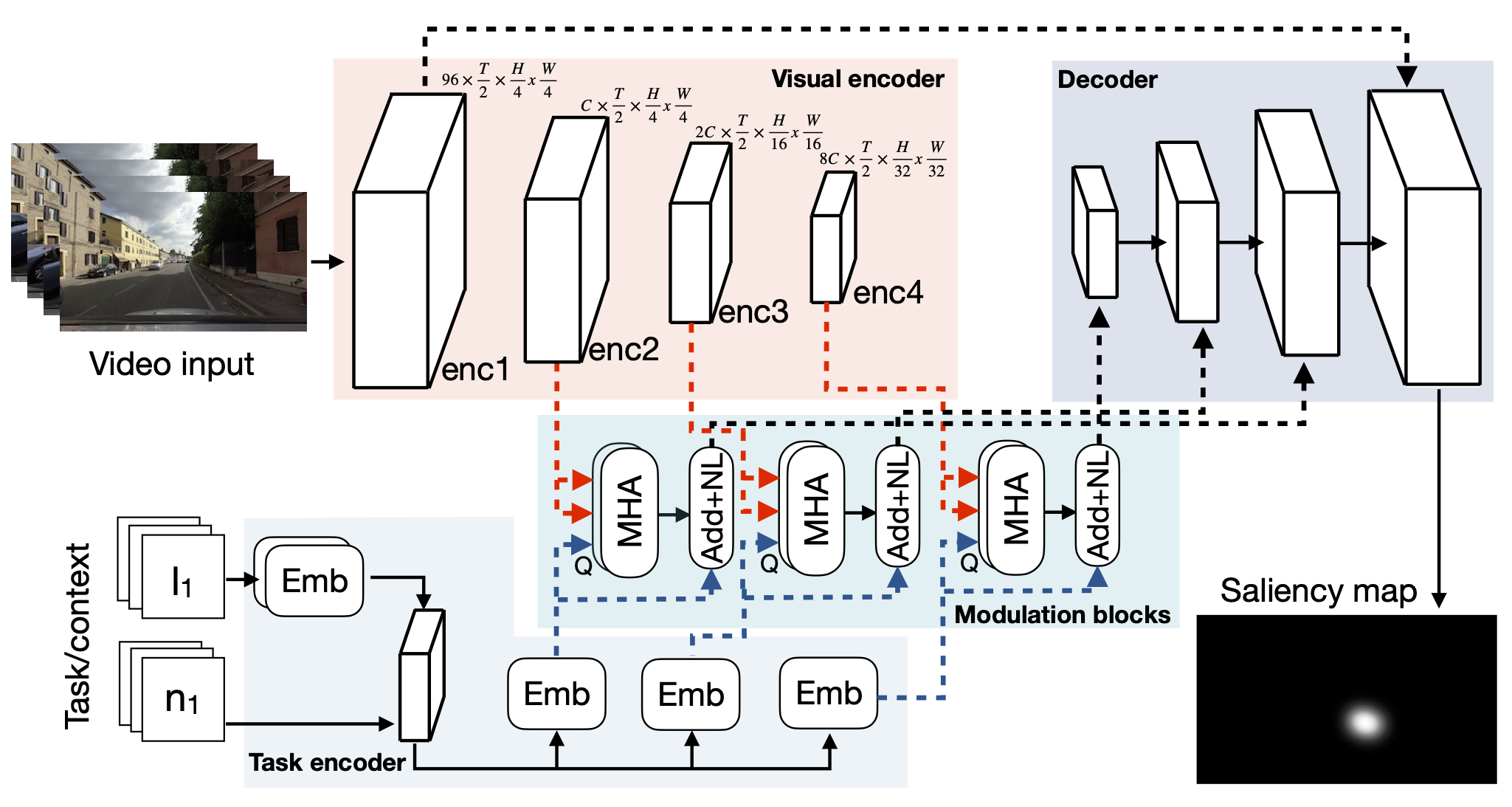
Accurate prediction of drivers' gaze is an important component of vision-based driver monitoring and assistive systems. Of particular interest are safety-critical episodes, such as performing maneuvers or crossing intersections. In such scenarios, drivers' gaze distribution changes significantly and becomes difficult to predict, especially if the task and context information is represented implicitly, as is common in many state-of-the-art models. However, explicit modeling of top-down factors affecting drivers' attention often requires additional information and annotations that may not be readily available. In this paper, we address the challenge of effective modeling of task and context with common sources of data for use in practical systems. To this end, we introduce SCOUT+, a task- and context-aware model for drivers' gaze prediction, which leverages route and map information inferred from commonly available GPS data. We evaluate our model on two datasets, DR(eye)VE and BDD-A, and demonstrate that using maps improves results compared to bottom-up models and reaches performance comparable to the top-down model SCOUT which relies on privileged ground truth information. Code is available at https://github.com/ykotseruba/SCOUT.
PDF Abstract

 DR(eye)VE
DR(eye)VE
 BDD-A
BDD-A
