MARTHE: Scheduling the Learning Rate Via Online Hypergradients
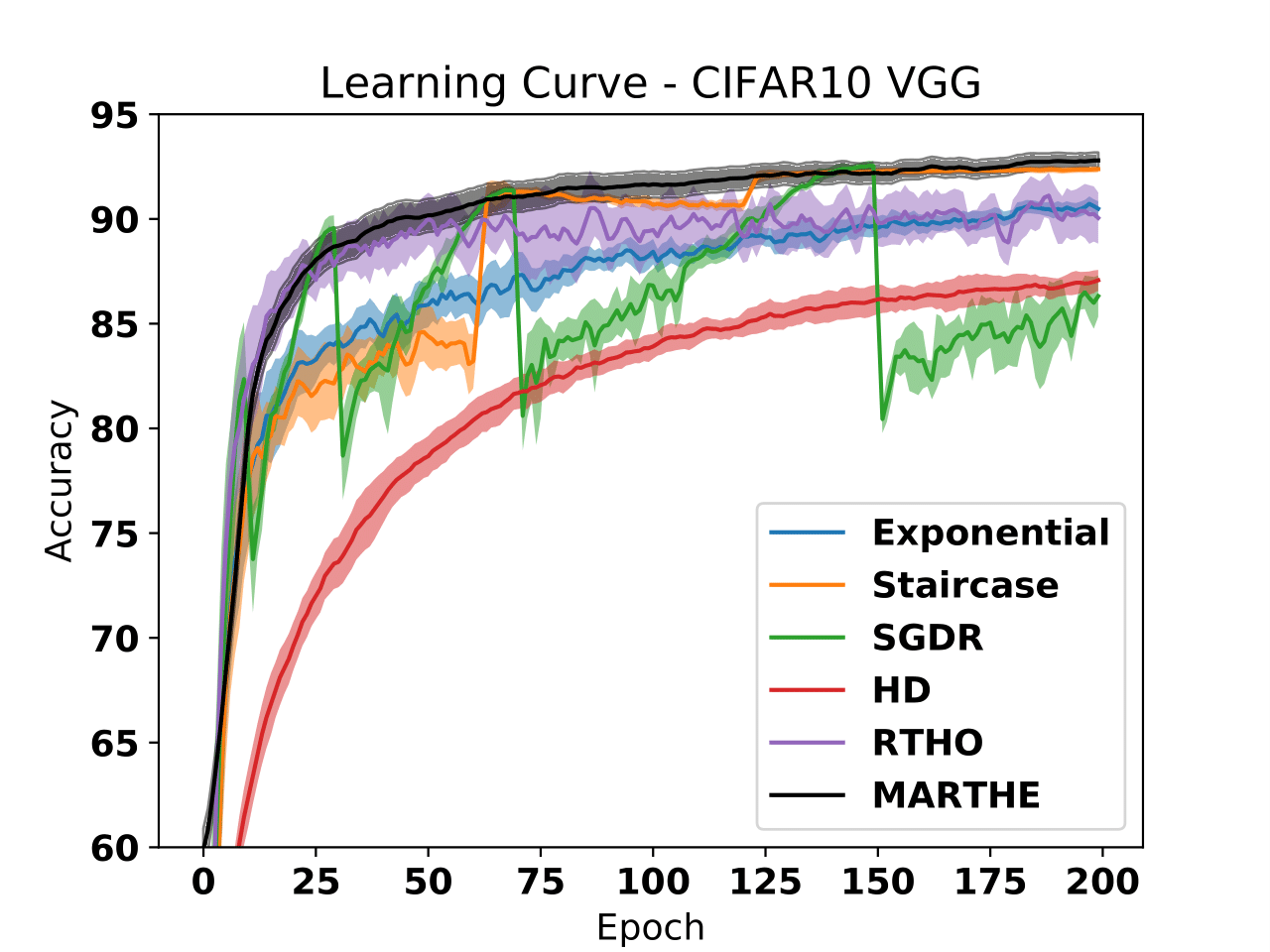
We study the problem of fitting task-specific learning rate schedules from the perspective of hyperparameter optimization, aiming at good generalization. We describe the structure of the gradient of a validation error w.r.t. the learning rate schedule -- the hypergradient. Based on this, we introduce MARTHE, a novel online algorithm guided by cheap approximations of the hypergradient that uses past information from the optimization trajectory to simulate future behaviour. It interpolates between two recent techniques, RTHO (Franceschi et al., 2017) and HD (Baydin et al. 2018), and is able to produce learning rate schedules that are more stable leading to models that generalize better.
PDF AbstractCode


 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
