Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
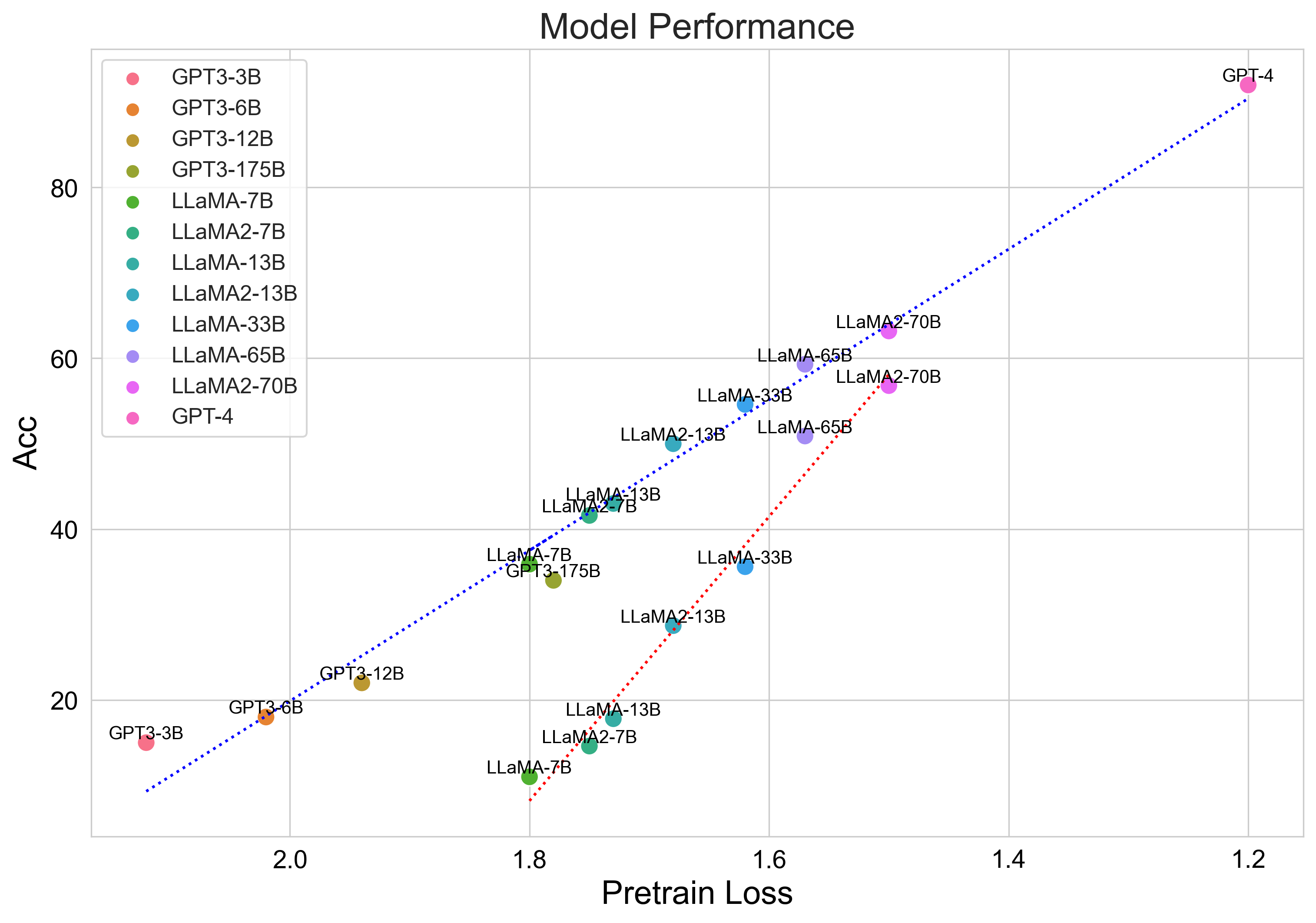
Mathematical reasoning is a challenging task for large language models (LLMs), while the scaling relationship of it with respect to LLM capacity is under-explored. In this paper, we investigate how the pre-training loss, supervised data amount, and augmented data amount influence the reasoning performances of a supervised LLM. We find that pre-training loss is a better indicator of the model's performance than the model's parameter count. We apply supervised fine-tuning (SFT) with different amounts of supervised data and empirically find a log-linear relation between data amount and model performance, and we find better models improve less with enlarged supervised datasets. To augment more data samples for improving model performances without any human effort, we propose to apply Rejection sampling Fine-Tuning (RFT). RFT uses supervised models to generate and collect correct reasoning paths as augmented fine-tuning datasets. We find with augmented samples containing more distinct reasoning paths, RFT improves mathematical reasoning performance more for LLMs. We also find RFT brings more improvement for less performant LLMs. Furthermore, we combine rejection samples from multiple models which push LLaMA-7B to an accuracy of 49.3\% on GSM8K which outperforms the supervised fine-tuning (SFT) accuracy of 35.9\% significantly.
PDF Abstract

Datasets
 GSM8K
GSM8K
Results from the Paper
 Ranked #100 on
Arithmetic Reasoning
on GSM8K
(using extra training data)
Ranked #100 on
Arithmetic Reasoning
on GSM8K
(using extra training data)
