Scalable Mask Annotation for Video Text Spotting
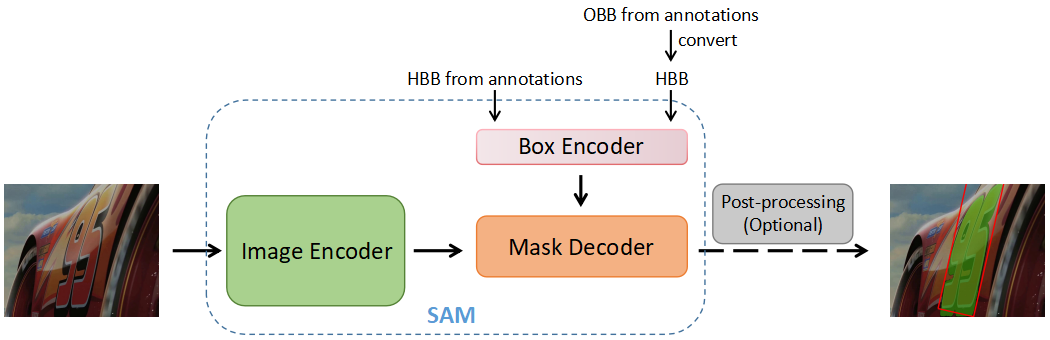
Video text spotting refers to localizing, recognizing, and tracking textual elements such as captions, logos, license plates, signs, and other forms of text within consecutive video frames. However, current datasets available for this task rely on quadrilateral ground truth annotations, which may result in including excessive background content and inaccurate text boundaries. Furthermore, methods trained on these datasets often produce prediction results in the form of quadrilateral boxes, which limits their ability to handle complex scenarios such as dense or curved text. To address these issues, we propose a scalable mask annotation pipeline called SAMText for video text spotting. SAMText leverages the SAM model to generate mask annotations for scene text images or video frames at scale. Using SAMText, we have created a large-scale dataset, SAMText-9M, that contains over 2,400 video clips sourced from existing datasets and over 9 million mask annotations. We have also conducted a thorough statistical analysis of the generated masks and their quality, identifying several research topics that could be further explored based on this dataset. The code and dataset will be released at \url{https://github.com/ViTAE-Transformer/SAMText}.
PDF Abstract
 COCO-Text
COCO-Text
 LSVTD
LSVTD
