Scalable Diffusion Models with State Space Backbone
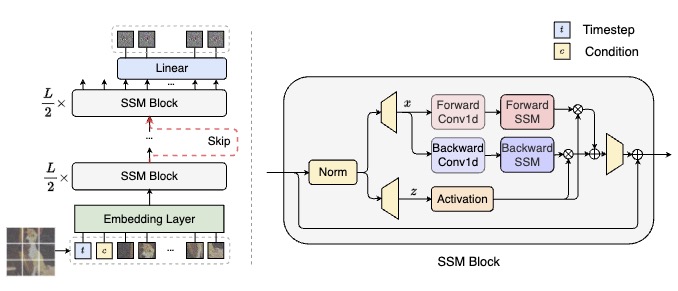
This paper presents a new exploration into a category of diffusion models built upon state space architecture. We endeavor to train diffusion models for image data, wherein the traditional U-Net backbone is supplanted by a state space backbone, functioning on raw patches or latent space. Given its notable efficacy in accommodating long-range dependencies, Diffusion State Space Models (DiS) are distinguished by treating all inputs including time, condition, and noisy image patches as tokens. Our assessment of DiS encompasses both unconditional and class-conditional image generation scenarios, revealing that DiS exhibits comparable, if not superior, performance to CNN-based or Transformer-based U-Net architectures of commensurate size. Furthermore, we analyze the scalability of DiS, gauged by the forward pass complexity quantified in Gflops. DiS models with higher Gflops, achieved through augmentation of depth/width or augmentation of input tokens, consistently demonstrate lower FID. In addition to demonstrating commendable scalability characteristics, DiS-H/2 models in latent space achieve performance levels akin to prior diffusion models on class-conditional ImageNet benchmarks at the resolution of 256$\times$256 and 512$\times$512, while significantly reducing the computational burden. The code and models are available at: https://github.com/feizc/DiS.
PDF Abstract


 CIFAR-10
CIFAR-10
 CelebA
CelebA
