Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
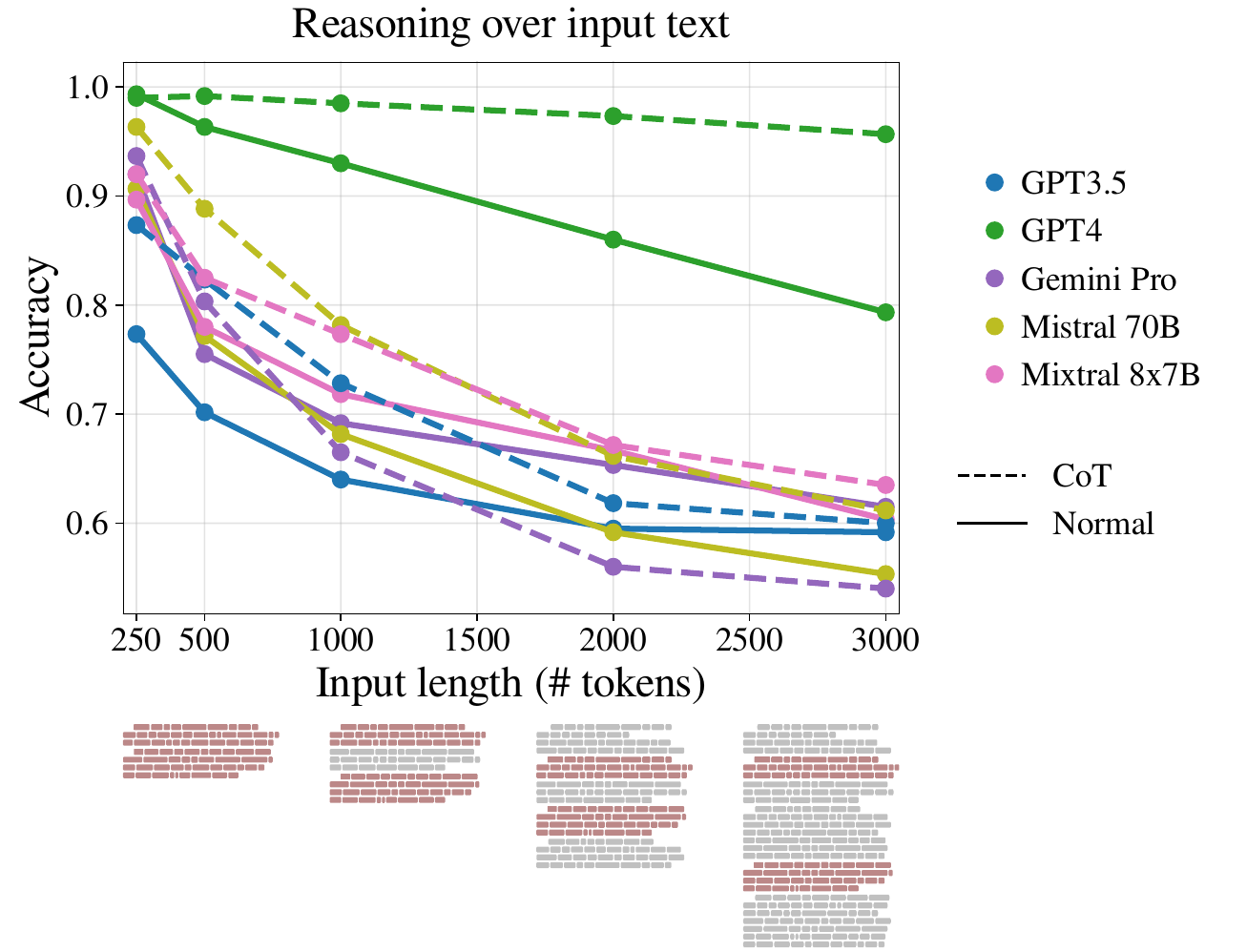
This paper explores the impact of extending input lengths on the capabilities of Large Language Models (LLMs). Despite LLMs advancements in recent times, their performance consistency across different input lengths is not well understood. We investigate this aspect by introducing a novel QA reasoning framework, specifically designed to assess the impact of input length. We isolate the effect of input length using multiple versions of the same sample, each being extended with padding of different lengths, types and locations. Our findings show a notable degradation in LLMs' reasoning performance at much shorter input lengths than their technical maximum. We show that the degradation trend appears in every version of our dataset, although at different intensities. Additionally, our study reveals that traditional perplexity metrics do not correlate with performance of LLMs' in long input reasoning tasks. We analyse our results and identify failure modes that can serve as useful guides for future research, potentially informing strategies to address the limitations observed in LLMs.
PDF Abstract BookCorpus
BookCorpus
