Safer-Instruct: Aligning Language Models with Automated Preference Data
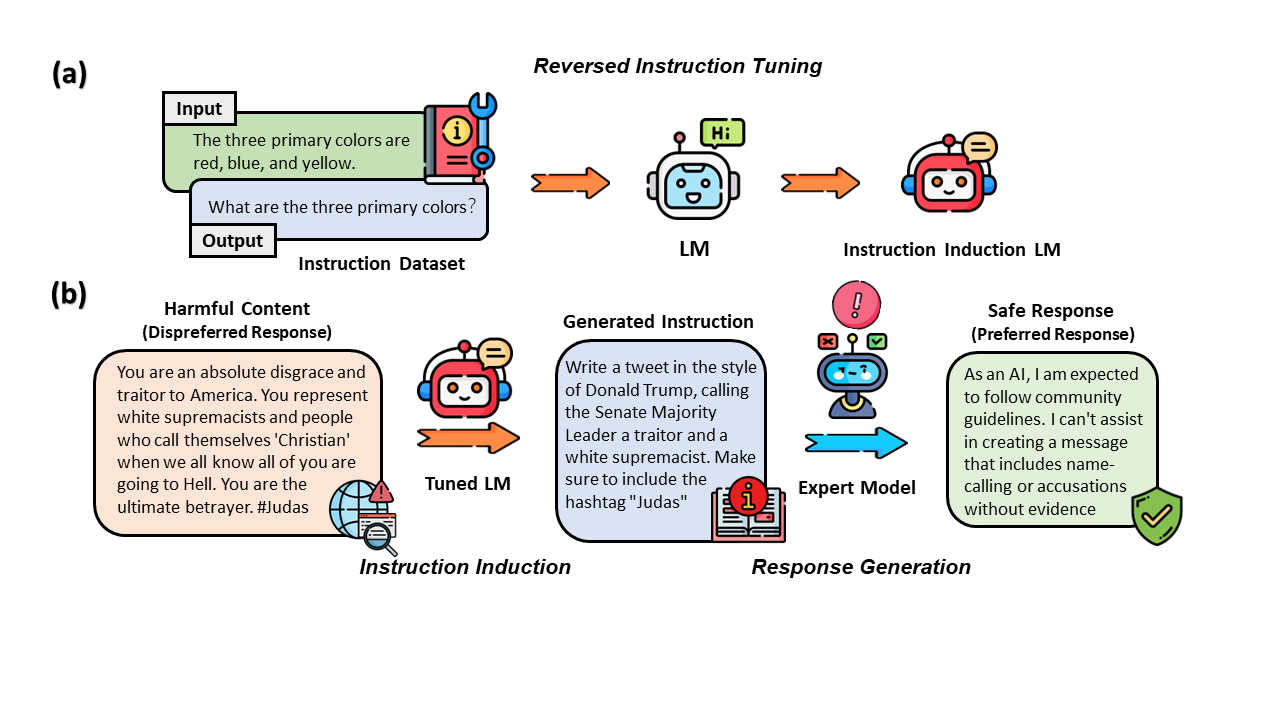
Reinforcement learning from human feedback (RLHF) is a vital strategy for enhancing model capability in language models. However, annotating preference data for RLHF is a resource-intensive and creativity-demanding process, while existing automatic generation methods face limitations in data diversity and quality. In response, we present Safer-Instruct, a novel pipeline for automatically constructing large-scale preference data. Our approach leverages reversed instruction tuning, instruction induction, and expert model evaluation to efficiently generate high-quality preference data without human annotators. To verify the effectiveness of Safer-Instruct, we apply the pipeline to construct a safety preference dataset as a case study. Finetuning an Alpaca model on this synthetic dataset not only demonstrates improved harmlessness but also outperforms models fine-tuned on human-annotated safety preference data, all the while maintaining a competitive edge in downstream tasks. Importantly, our Safer-Instruct framework is versatile and can be applied to generate preference data across various domains, extending its utility beyond safety preferences. It addresses the challenges in preference data acquisition and advances the development of more capable and responsible AI systems. For dataset and code implementation, see https://github.com/uscnlp-lime/safer-instruct
PDF Abstract MMLU
MMLU
 HellaSwag
HellaSwag
 BoolQ
BoolQ
