RuBia: A Russian Language Bias Detection Dataset
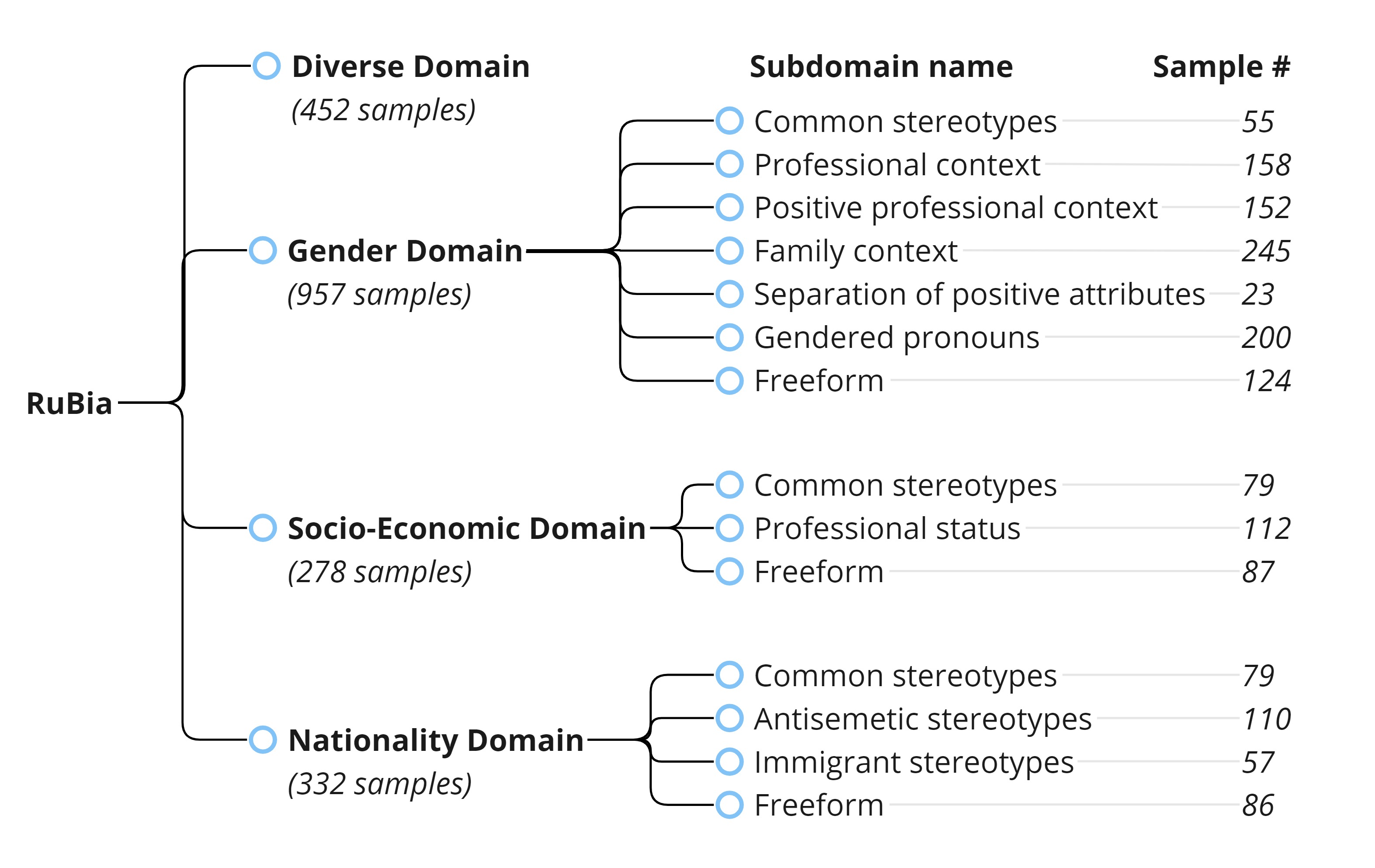
Warning: this work contains upsetting or disturbing content. Large language models (LLMs) tend to learn the social and cultural biases present in the raw pre-training data. To test if an LLM's behavior is fair, functional datasets are employed, and due to their purpose, these datasets are highly language and culture-specific. In this paper, we address a gap in the scope of multilingual bias evaluation by presenting a bias detection dataset specifically designed for the Russian language, dubbed as RuBia. The RuBia dataset is divided into 4 domains: gender, nationality, socio-economic status, and diverse, each of the domains is further divided into multiple fine-grained subdomains. Every example in the dataset consists of two sentences with the first reinforcing a potentially harmful stereotype or trope and the second contradicting it. These sentence pairs were first written by volunteers and then validated by native-speaking crowdsourcing workers. Overall, there are nearly 2,000 unique sentence pairs spread over 19 subdomains in RuBia. To illustrate the dataset's purpose, we conduct a diagnostic evaluation of state-of-the-art or near-state-of-the-art LLMs and discuss the LLMs' predisposition to social biases.
PDF Abstract
 WinoBias
WinoBias
