Robust Deep Reinforcement Learning against Adversarial Perturbations on State Observations
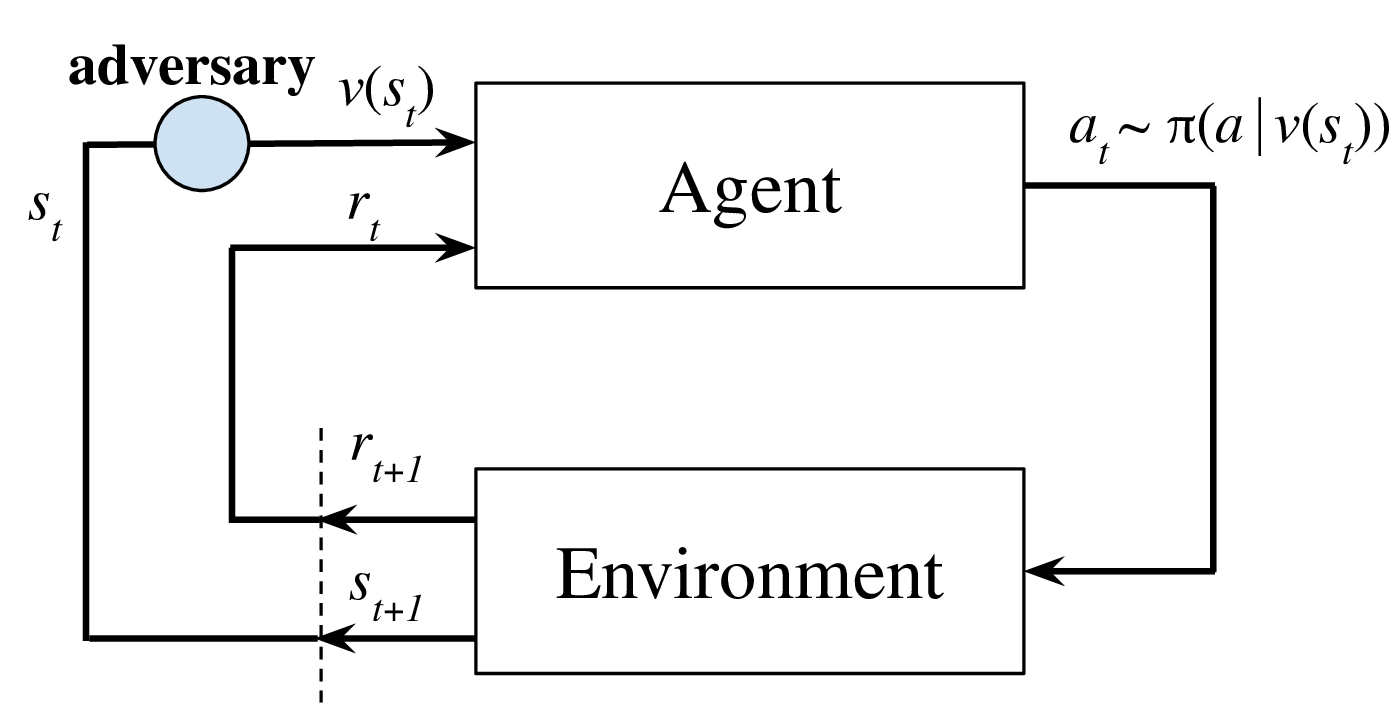
A deep reinforcement learning (DRL) agent observes its states through observations, which may contain natural measurement errors or adversarial noises. Since the observations deviate from the true states, they can mislead the agent into making suboptimal actions. Several works have shown this vulnerability via adversarial attacks, but existing approaches on improving the robustness of DRL under this setting have limited success and lack for theoretical principles. We show that naively applying existing techniques on improving robustness for classification tasks, like adversarial training, is ineffective for many RL tasks. We propose the state-adversarial Markov decision process (SA-MDP) to study the fundamental properties of this problem, and develop a theoretically principled policy regularization which can be applied to a large family of DRL algorithms, including proximal policy optimization (PPO), deep deterministic policy gradient (DDPG) and deep Q networks (DQN), for both discrete and continuous action control problems. We significantly improve the robustness of PPO, DDPG and DQN agents under a suite of strong white box adversarial attacks, including new attacks of our own. Additionally, we find that a robust policy noticeably improves DRL performance even without an adversary in a number of environments. Our code is available at https://github.com/chenhongge/StateAdvDRL.
PDF Abstract NeurIPS 2020 PDF NeurIPS 2020 Abstract


 OpenAI Gym
OpenAI Gym
