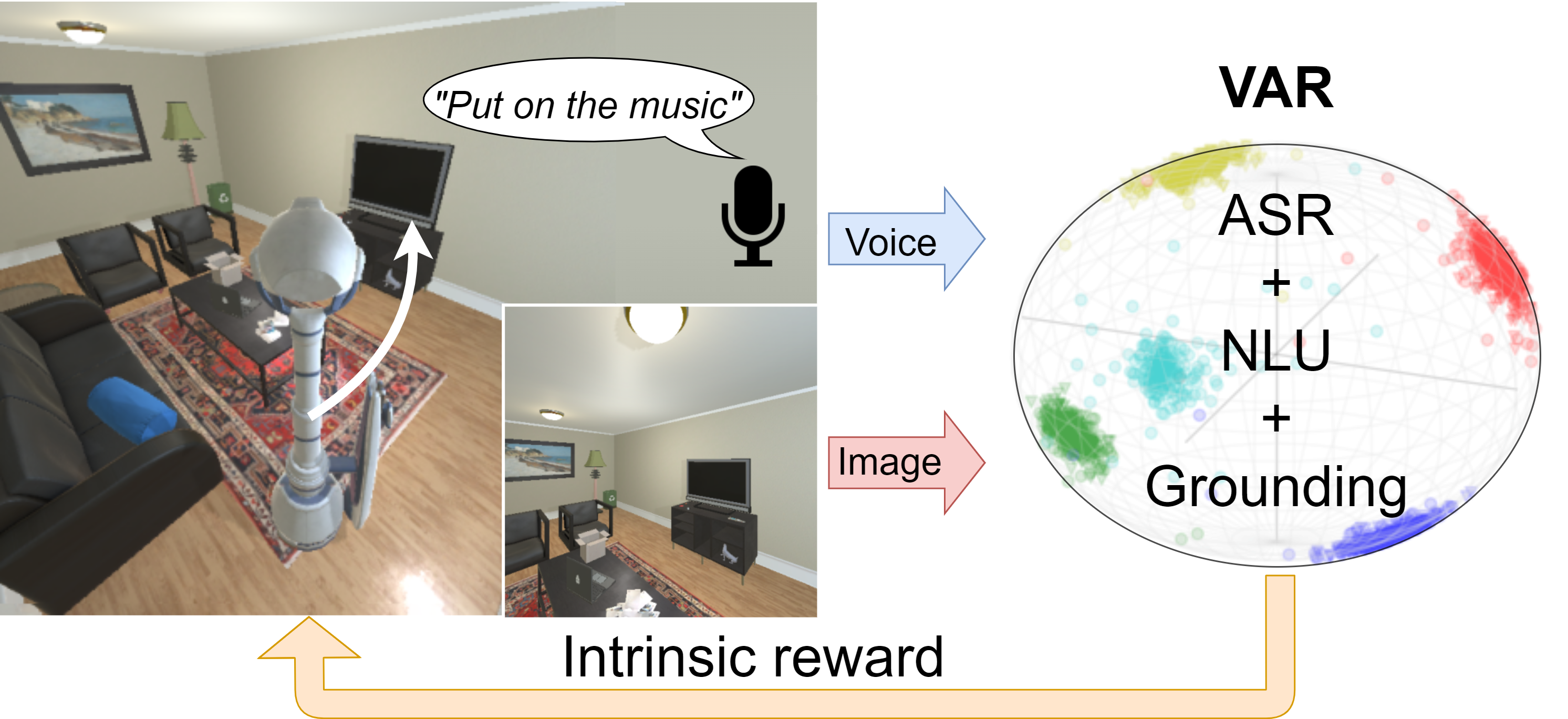
Learning Visual-Audio Representations for Voice-Controlled Robots
Based on the recent advancements in representation learning, we propose a novel pipeline for task-oriented voice-controlled robots with raw sensor inputs. Previous methods rely on a large number of labels and task-specific reward functions. Not only can such an approach hardly be improved after the deployment, but also has limited generalization across robotic platforms and tasks. To address these problems, our pipeline first learns a visual-audio representation (VAR) that associates images and sound commands. Then the robot learns to fulfill the sound command via reinforcement learning using the reward generated by the VAR. We demonstrate our approach with various sound types, robots, and tasks. We show that our method outperforms previous work with much fewer labels. We show in both the simulated and real-world experiments that the system can self-improve in previously unseen scenarios given a reasonable number of newly labeled data.
PDF Abstract

 Speech Commands
Speech Commands
 NSynth
NSynth
