RoAST: Robustifying Language Models via Adversarial Perturbation with Selective Training
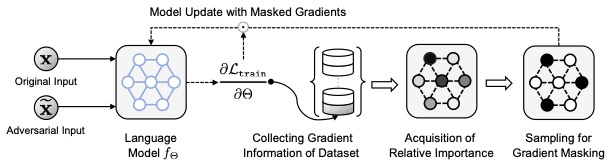
Fine-tuning pre-trained language models (LMs) has become the de facto standard in many NLP tasks. Nevertheless, fine-tuned LMs are still prone to robustness issues, such as adversarial robustness and model calibration. Several perspectives of robustness for LMs have been studied independently, but lacking a unified consideration in multiple perspectives. In this paper, we propose Robustifying LMs via Adversarial perturbation with Selective Training (RoAST), a simple yet effective fine-tuning technique to enhance the multi-perspective robustness of LMs in a unified way. RoAST effectively incorporates two important sources for the model robustness, robustness on the perturbed inputs and generalizable knowledge in pre-trained LMs. To be specific, RoAST introduces adversarial perturbation during fine-tuning while the model parameters are selectively updated upon their relative importance to minimize unnecessary deviation. Under a unified evaluation of fine-tuned LMs by incorporating four representative perspectives of model robustness, we demonstrate the effectiveness of RoAST compared to state-of-the-art fine-tuning methods on six different types of LMs, which indicates its usefulness in practice.
PDF Abstract

 GLUE
GLUE
 SST
SST
 MultiNLI
MultiNLI
