RLHF Workflow: From Reward Modeling to Online RLHF
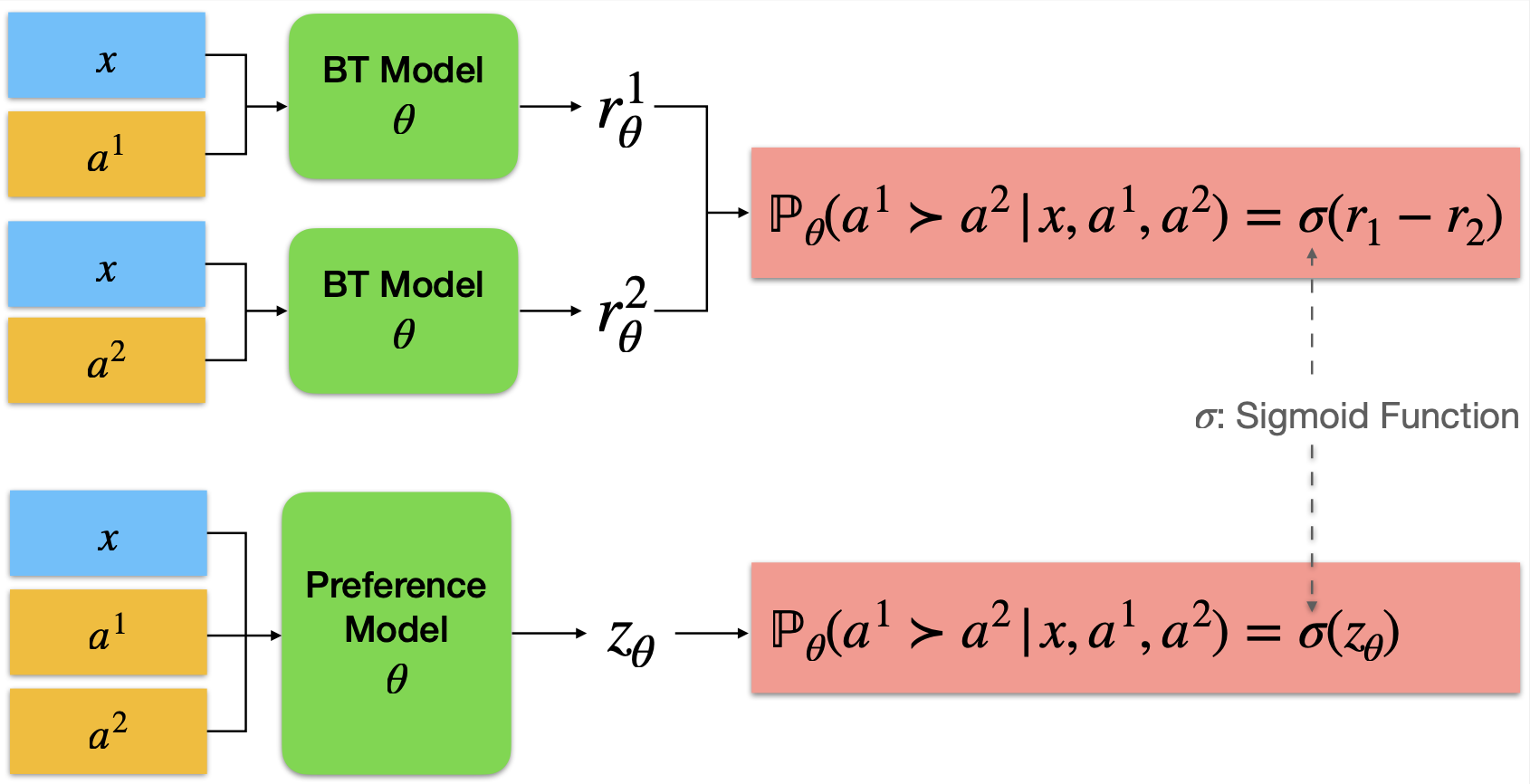
We present the workflow of Online Iterative Reinforcement Learning from Human Feedback (RLHF) in this technical report, which is widely reported to outperform its offline counterpart by a large margin in the recent large language model (LLM) literature. However, existing open-source RLHF projects are still largely confined to the offline learning setting. In this technical report, we aim to fill in this gap and provide a detailed recipe that is easy to reproduce for online iterative RLHF. In particular, since online human feedback is usually infeasible for open-source communities with limited resources, we start by constructing preference models using a diverse set of open-source datasets and use the constructed proxy preference model to approximate human feedback. Then, we discuss the theoretical insights and algorithmic principles behind online iterative RLHF, followed by a detailed practical implementation. Our trained LLM, SFR-Iterative-DPO-LLaMA-3-8B-R, achieves impressive performance on LLM chatbot benchmarks, including AlpacaEval-2, Arena-Hard, and MT-Bench, as well as other academic benchmarks such as HumanEval and TruthfulQA. We have shown that supervised fine-tuning (SFT) and iterative RLHF can obtain state-of-the-art performance with fully open-source datasets. Further, we have made our models, curated datasets, and comprehensive step-by-step code guidebooks publicly available. Please refer to https://github.com/RLHFlow/RLHF-Reward-Modeling and https://github.com/RLHFlow/Online-RLHF for more detailed information.
PDF Abstract Spaces
Spaces




 MMLU
MMLU
 GSM8K
GSM8K
 HumanEval
HumanEval
 TruthfulQA
TruthfulQA
 AlpacaEval
AlpacaEval
