Rissanen Data Analysis: Examining Dataset Characteristics via Description Length
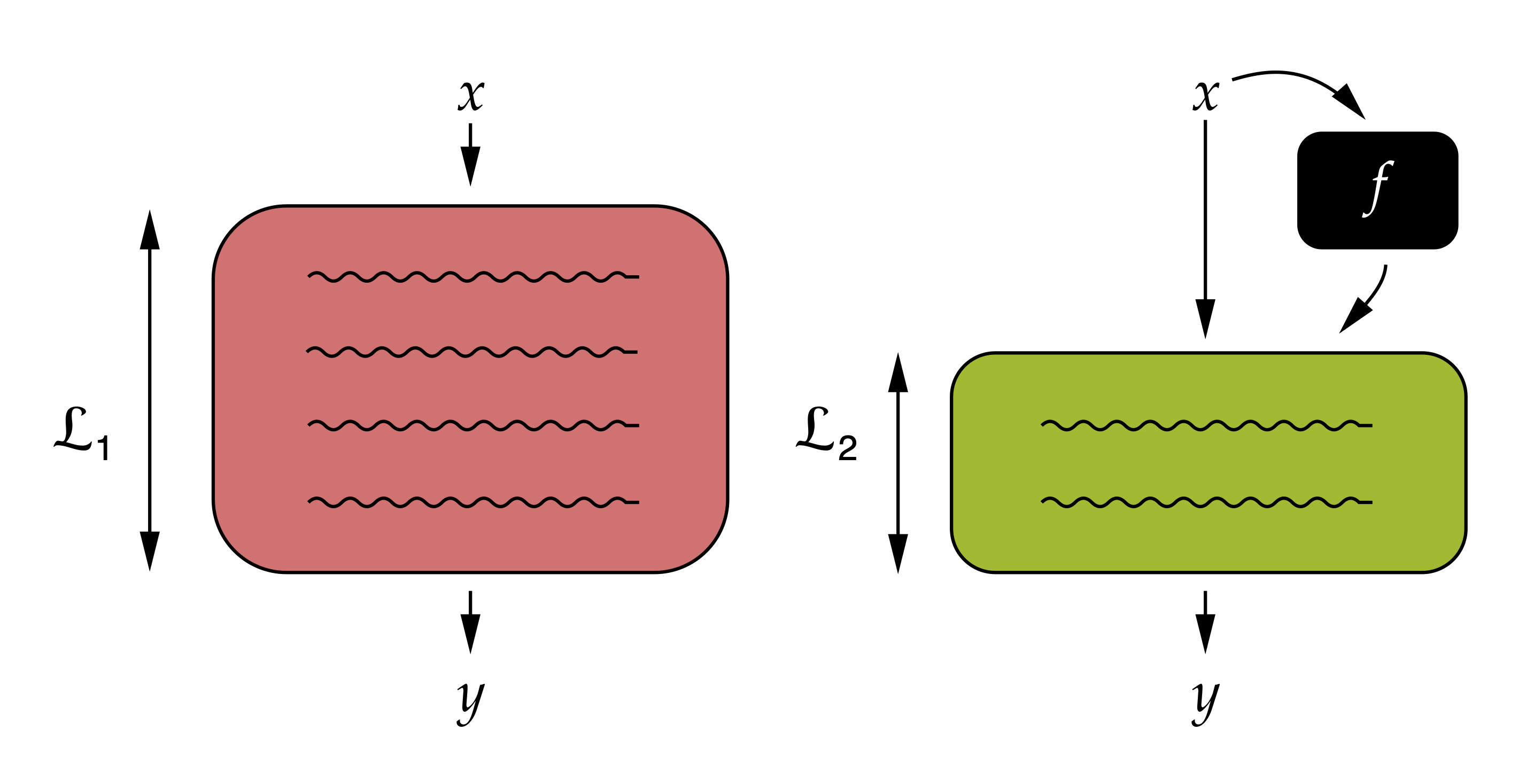
We introduce a method to determine if a certain capability helps to achieve an accurate model of given data. We view labels as being generated from the inputs by a program composed of subroutines with different capabilities, and we posit that a subroutine is useful if and only if the minimal program that invokes it is shorter than the one that does not. Since minimum program length is uncomputable, we instead estimate the labels' minimum description length (MDL) as a proxy, giving us a theoretically-grounded method for analyzing dataset characteristics. We call the method Rissanen Data Analysis (RDA) after the father of MDL, and we showcase its applicability on a wide variety of settings in NLP, ranging from evaluating the utility of generating subquestions before answering a question, to analyzing the value of rationales and explanations, to investigating the importance of different parts of speech, and uncovering dataset gender bias.
PDF Abstract ICLR Workshop 2021 PDF ICLR Workshop 2021 Abstract Colab
Colab

 GLUE
GLUE
 SST
SST
 MultiNLI
MultiNLI
 SNLI
SNLI
 QNLI
QNLI
 MRPC
MRPC
 CoLA
CoLA
 CLEVR
CLEVR
 HotpotQA
HotpotQA
 ANLI
ANLI
 e-SNLI
e-SNLI
