Reward Collapse in Aligning Large Language Models
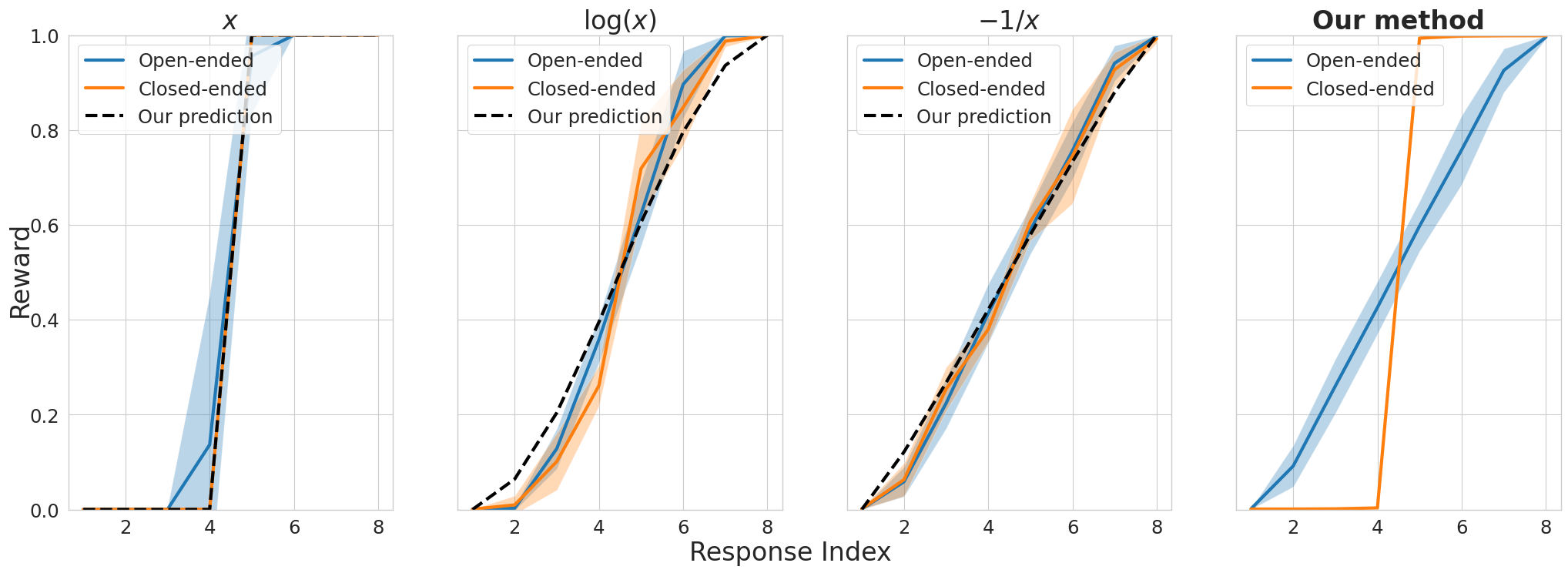
The extraordinary capabilities of large language models (LLMs) such as ChatGPT and GPT-4 are in part unleashed by aligning them with reward models that are trained on human preferences, which are often represented as rankings of responses to prompts. In this paper, we document the phenomenon of \textit{reward collapse}, an empirical observation where the prevailing ranking-based approach results in an \textit{identical} reward distribution \textit{regardless} of the prompts during the terminal phase of training. This outcome is undesirable as open-ended prompts like ``write a short story about your best friend'' should yield a continuous range of rewards for their completions, while specific prompts like ``what is the capital of New Zealand'' should generate either high or low rewards. Our theoretical investigation reveals that reward collapse is primarily due to the insufficiency of the ranking-based objective function to incorporate prompt-related information during optimization. This insight allows us to derive closed-form expressions for the reward distribution associated with a set of utility functions in an asymptotic regime. To overcome reward collapse, we introduce a prompt-aware optimization scheme that provably admits a prompt-dependent reward distribution within the interpolating regime. Our experimental results suggest that our proposed prompt-aware utility functions significantly alleviate reward collapse during the training of reward models.
PDF Abstract
