Revisiting Temporal Modeling for Video-based Person ReID
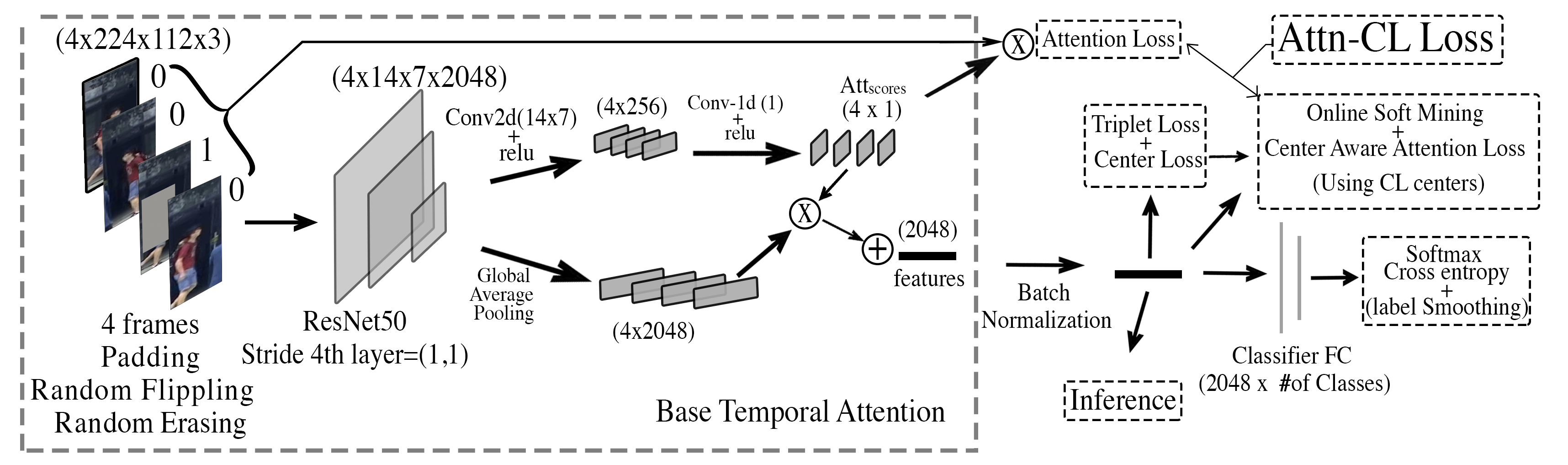
Video-based person reID is an important task, which has received much attention in recent years due to the increasing demand in surveillance and camera networks. A typical video-based person reID system consists of three parts: an image-level feature extractor (e.g. CNN), a temporal modeling method to aggregate temporal features and a loss function. Although many methods on temporal modeling have been proposed, it is hard to directly compare these methods, because the choice of feature extractor and loss function also have a large impact on the final performance. We comprehensively study and compare four different temporal modeling methods (temporal pooling, temporal attention, RNN and 3D convnets) for video-based person reID. We also propose a new attention generation network which adopts temporal convolution to extract temporal information among frames. The evaluation is done on the MARS dataset, and our methods outperform state-of-the-art methods by a large margin. Our source codes are released at https://github.com/jiyanggao/Video-Person-ReID.
PDF Abstract
 MARS
MARS
