Revisiting randomized choices in isolation forests
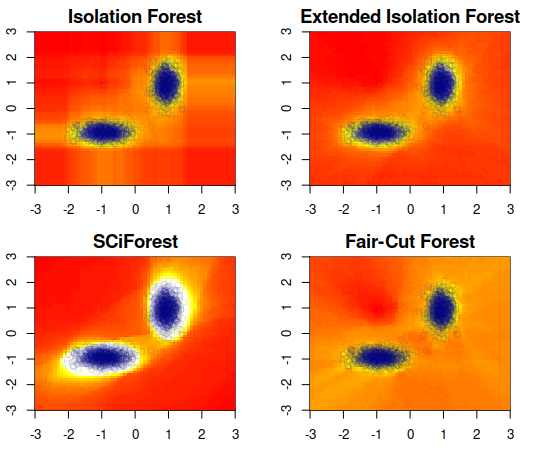
Isolation forest or "iForest" is an intuitive and widely used algorithm for anomaly detection that follows a simple yet effective idea: in a given data distribution, if a threshold (split point) is selected uniformly at random within the range of some variable and data points are divided according to whether they are greater or smaller than this threshold, outlier points are more likely to end up alone or in the smaller partition. The original procedure suggested the choice of variable to split and split point within a variable to be done uniformly at random at each step, but this paper shows that "clustered" diverse outliers - oftentimes a more interesting class of outliers than others - can be more easily identified by applying a non-uniformly-random choice of variables and/or thresholds. Different split guiding criteria are compared and some are found to result in significantly better outlier discrimination for certain classes of outliers.
PDF Abstract

