Revisiting Few-sample BERT Fine-tuning
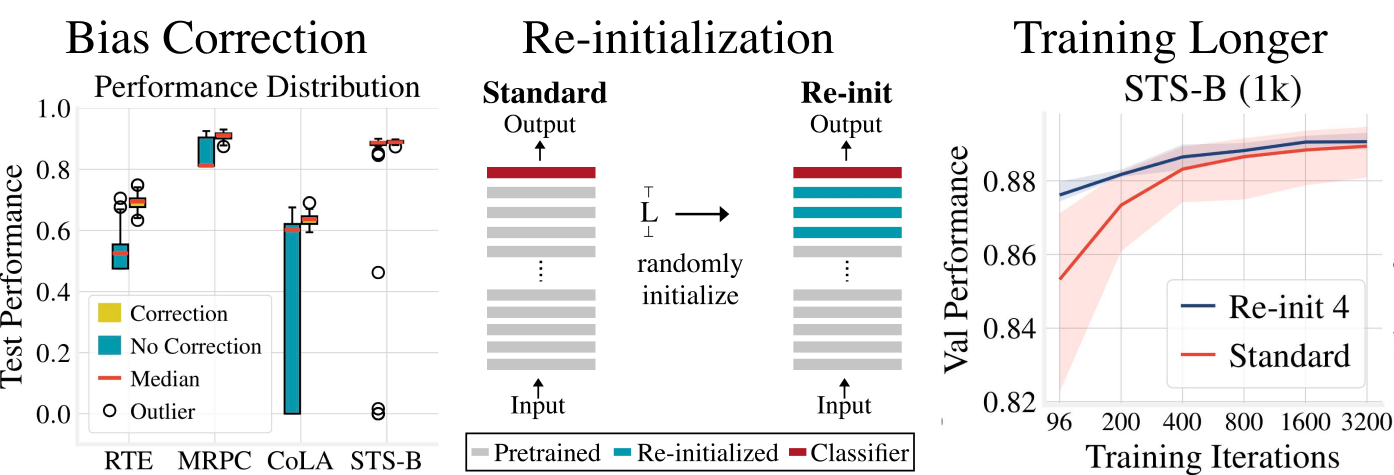
This paper is a study of fine-tuning of BERT contextual representations, with focus on commonly observed instabilities in few-sample scenarios. We identify several factors that cause this instability: the common use of a non-standard optimization method with biased gradient estimation; the limited applicability of significant parts of the BERT network for down-stream tasks; and the prevalent practice of using a pre-determined, and small number of training iterations. We empirically test the impact of these factors, and identify alternative practices that resolve the commonly observed instability of the process. In light of these observations, we re-visit recently proposed methods to improve few-sample fine-tuning with BERT and re-evaluate their effectiveness. Generally, we observe the impact of these methods diminishes significantly with our modified process.
PDF Abstract ICLR 2021 PDF ICLR 2021 Abstract
 GLUE
GLUE
 SST
SST
 MultiNLI
MultiNLI
 QNLI
QNLI
 MRPC
MRPC
 CoLA
CoLA
