Revealing Single Frame Bias for Video-and-Language Learning
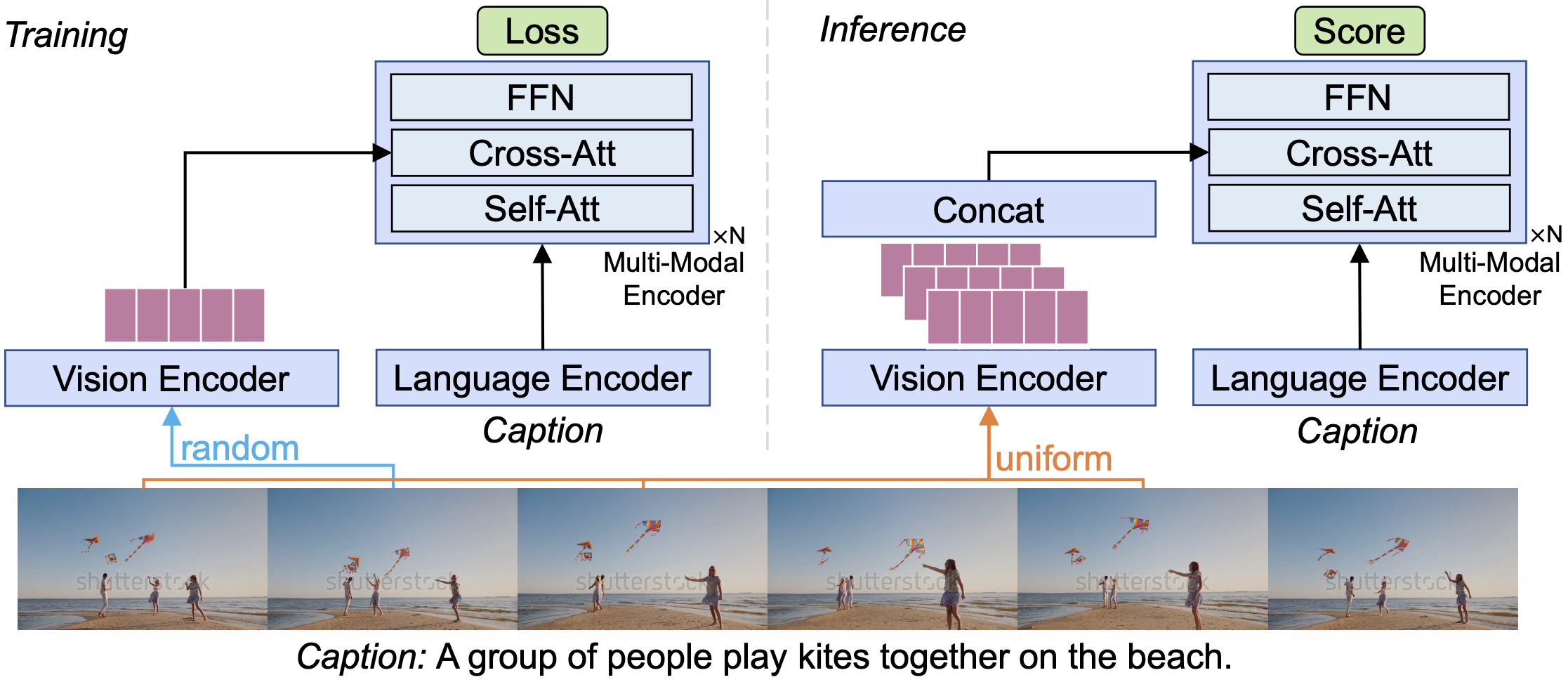
Training an effective video-and-language model intuitively requires multiple frames as model inputs. However, it is unclear whether using multiple frames is beneficial to downstream tasks, and if yes, whether the performance gain is worth the drastically-increased computation and memory costs resulting from using more frames. In this work, we explore single-frame models for video-and-language learning. On a diverse set of video-and-language tasks (including text-to-video retrieval and video question answering), we show the surprising result that, with large-scale pre-training and a proper frame ensemble strategy at inference time, a single-frame trained model that does not consider temporal information can achieve better performance than existing methods that use multiple frames for training. This result reveals the existence of a strong "static appearance bias" in popular video-and-language datasets. Therefore, to allow for a more comprehensive evaluation of video-and-language models, we propose two new retrieval tasks based on existing fine-grained action recognition datasets that encourage temporal modeling. Our code is available at https://github.com/jayleicn/singularity
PDF AbstractCode





 Flickr30k
Flickr30k
 ActivityNet
ActivityNet
 MSR-VTT
MSR-VTT
 HowTo100M
HowTo100M
 Something-Something V2
Something-Something V2
 DiDeMo
DiDeMo
 WebVid
WebVid
 CC12M
CC12M
 ActivityNet-QA
ActivityNet-QA
Results from the Paper
 Ranked #5 on
Video Retrieval
on SSv2-template retrieval
(using extra training data)
Ranked #5 on
Video Retrieval
on SSv2-template retrieval
(using extra training data)
