RetICL: Sequential Retrieval of In-Context Examples with Reinforcement Learning
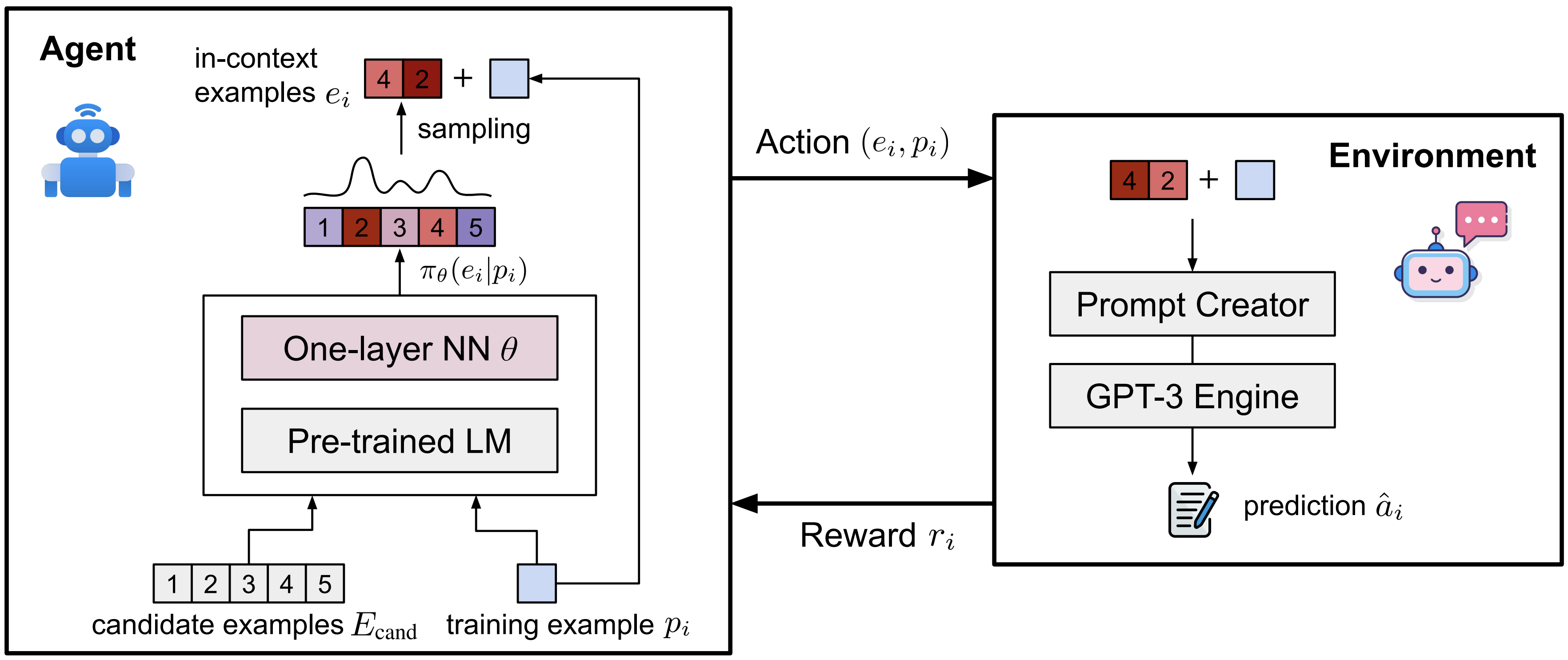
Recent developments in large pre-trained language models have enabled unprecedented performance on a variety of downstream tasks. Achieving best performance with these models often leverages in-context learning, where a model performs a (possibly new) task given one or more examples. However, recent work has shown that the choice of examples can have a large impact on task performance and that finding an optimal set of examples is non-trivial. While there are many existing methods for selecting in-context examples, they generally score examples independently, ignoring the dependency between them and the order in which they are provided to the model. In this work, we propose Retrieval for In-Context Learning (RetICL), a learnable method for modeling and optimally selecting examples sequentially for in-context learning. We frame the problem of sequential example selection as a Markov decision process and train an example retriever using reinforcement learning. We evaluate RetICL on math word problem solving and scientific question answering tasks and show that it consistently outperforms or matches heuristic and learnable baselines. We also use case studies to show that RetICL implicitly learns representations of problem solving strategies.
PDF Abstract




 GSM8K
GSM8K
 QASC
QASC
