Rethinking Uncertainly Missing and Ambiguous Visual Modality in Multi-Modal Entity Alignment
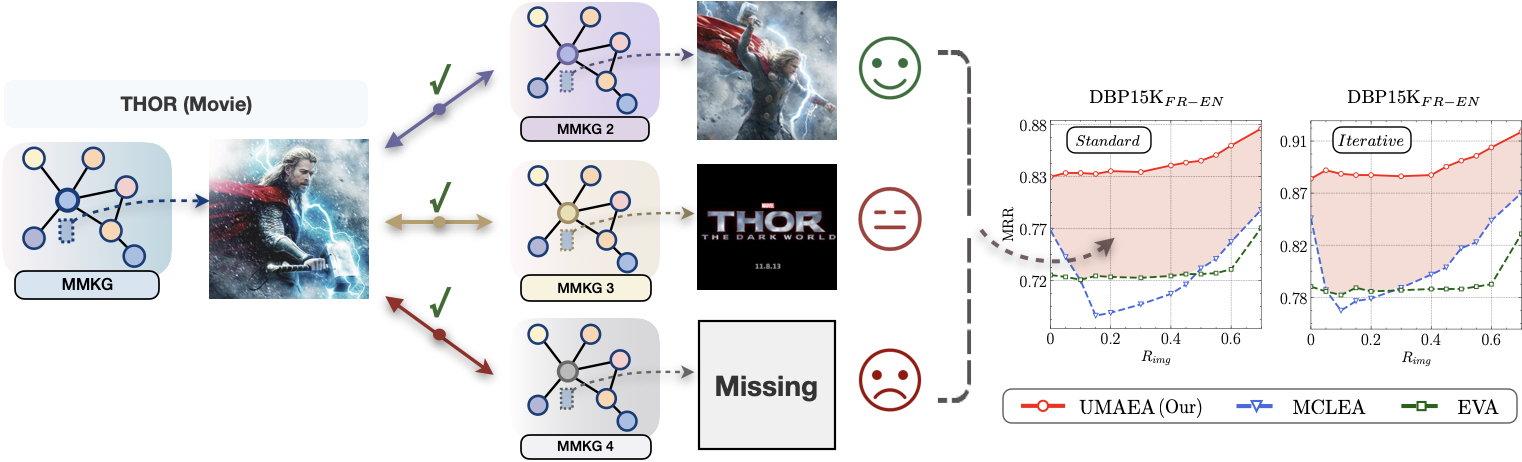
As a crucial extension of entity alignment (EA), multi-modal entity alignment (MMEA) aims to identify identical entities across disparate knowledge graphs (KGs) by exploiting associated visual information. However, existing MMEA approaches primarily concentrate on the fusion paradigm of multi-modal entity features, while neglecting the challenges presented by the pervasive phenomenon of missing and intrinsic ambiguity of visual images. In this paper, we present a further analysis of visual modality incompleteness, benchmarking latest MMEA models on our proposed dataset MMEA-UMVM, where the types of alignment KGs covering bilingual and monolingual, with standard (non-iterative) and iterative training paradigms to evaluate the model performance. Our research indicates that, in the face of modality incompleteness, models succumb to overfitting the modality noise, and exhibit performance oscillations or declines at high rates of missing modality. This proves that the inclusion of additional multi-modal data can sometimes adversely affect EA. To address these challenges, we introduce UMAEA , a robust multi-modal entity alignment approach designed to tackle uncertainly missing and ambiguous visual modalities. It consistently achieves SOTA performance across all 97 benchmark splits, significantly surpassing existing baselines with limited parameters and time consumption, while effectively alleviating the identified limitations of other models. Our code and benchmark data are available at https://github.com/zjukg/UMAEA.
PDF AbstractCode


Datasets
 UMVM
UMVM
Results from the Paper
 Ranked #1 on
Multi-modal Entity Alignment
on UMVM-oea-d-w-v2
(using extra training data)
Ranked #1 on
Multi-modal Entity Alignment
on UMVM-oea-d-w-v2
(using extra training data)
