Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models
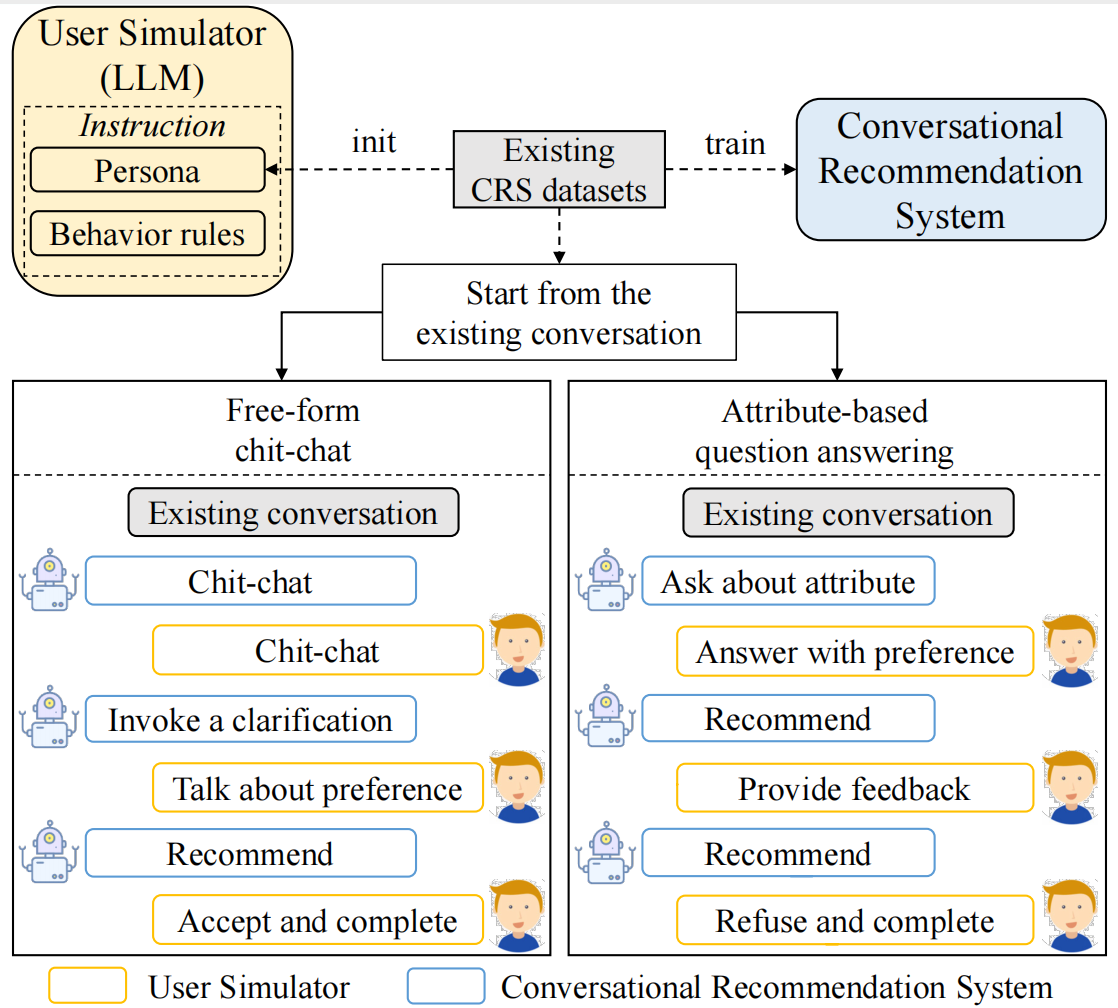
The recent success of large language models (LLMs) has shown great potential to develop more powerful conversational recommender systems (CRSs), which rely on natural language conversations to satisfy user needs. In this paper, we embark on an investigation into the utilization of ChatGPT for conversational recommendation, revealing the inadequacy of the existing evaluation protocol. It might over-emphasize the matching with the ground-truth items or utterances generated by human annotators, while neglecting the interactive nature of being a capable CRS. To overcome the limitation, we further propose an interactive Evaluation approach based on LLMs named iEvaLM that harnesses LLM-based user simulators. Our evaluation approach can simulate various interaction scenarios between users and systems. Through the experiments on two publicly available CRS datasets, we demonstrate notable improvements compared to the prevailing evaluation protocol. Furthermore, we emphasize the evaluation of explainability, and ChatGPT showcases persuasive explanation generation for its recommendations. Our study contributes to a deeper comprehension of the untapped potential of LLMs for CRSs and provides a more flexible and easy-to-use evaluation framework for future research endeavors. The codes and data are publicly available at https://github.com/RUCAIBox/iEvaLM-CRS.
PDF Abstract


 ReDial
ReDial
