Towards Robust Vision Transformer
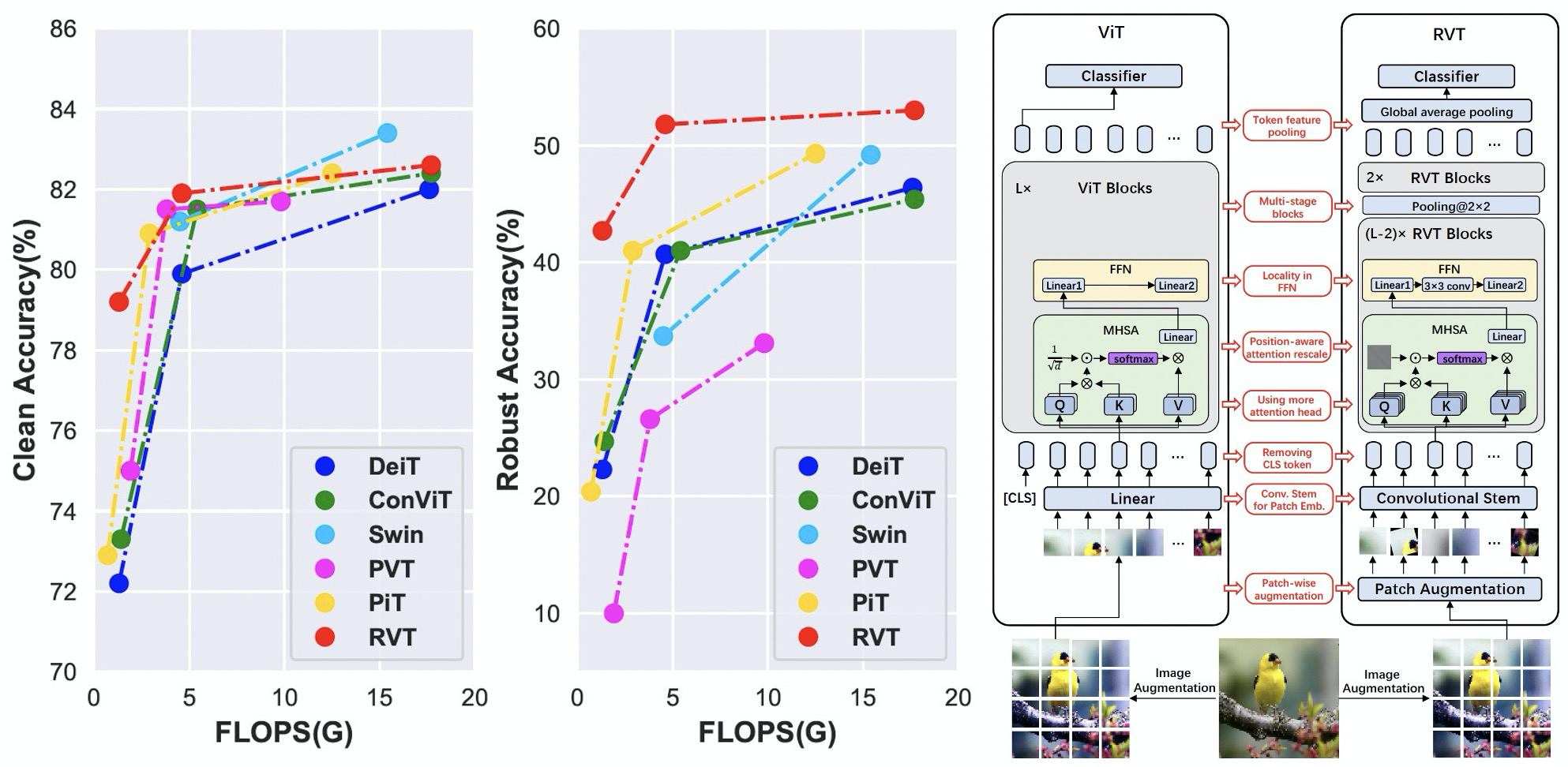
Recent advances on Vision Transformer (ViT) and its improved variants have shown that self-attention-based networks surpass traditional Convolutional Neural Networks (CNNs) in most vision tasks. However, existing ViTs focus on the standard accuracy and computation cost, lacking the investigation of the intrinsic influence on model robustness and generalization. In this work, we conduct systematic evaluation on components of ViTs in terms of their impact on robustness to adversarial examples, common corruptions and distribution shifts. We find some components can be harmful to robustness. By using and combining robust components as building blocks of ViTs, we propose Robust Vision Transformer (RVT), which is a new vision transformer and has superior performance with strong robustness. We further propose two new plug-and-play techniques called position-aware attention scaling and patch-wise augmentation to augment our RVT, which we abbreviate as RVT*. The experimental results on ImageNet and six robustness benchmarks show the advanced robustness and generalization ability of RVT compared with previous ViTs and state-of-the-art CNNs. Furthermore, RVT-S* also achieves Top-1 rank on multiple robustness leaderboards including ImageNet-C and ImageNet-Sketch. The code will be available at \url{https://github.com/alibaba/easyrobust}.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract


 ImageNet
ImageNet
 ImageNet-C
ImageNet-C
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
 ImageNet-Sketch
ImageNet-Sketch

