ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech
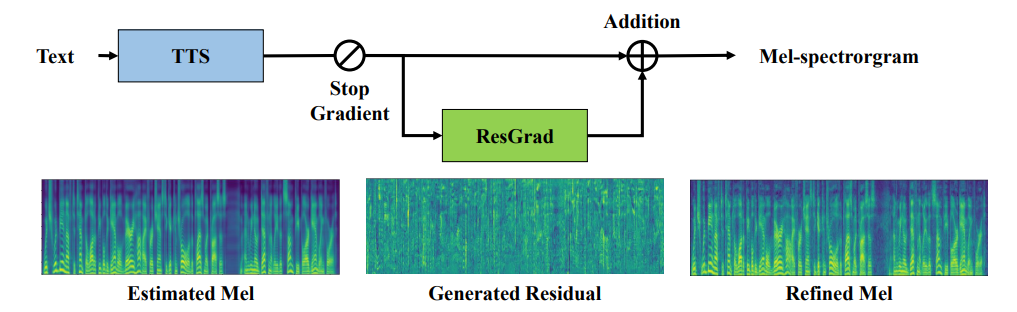
Denoising Diffusion Probabilistic Models (DDPMs) are emerging in text-to-speech (TTS) synthesis because of their strong capability of generating high-fidelity samples. However, their iterative refinement process in high-dimensional data space results in slow inference speed, which restricts their application in real-time systems. Previous works have explored speeding up by minimizing the number of inference steps but at the cost of sample quality. In this work, to improve the inference speed for DDPM-based TTS model while achieving high sample quality, we propose ResGrad, a lightweight diffusion model which learns to refine the output spectrogram of an existing TTS model (e.g., FastSpeech 2) by predicting the residual between the model output and the corresponding ground-truth speech. ResGrad has several advantages: 1) Compare with other acceleration methods for DDPM which need to synthesize speech from scratch, ResGrad reduces the complexity of task by changing the generation target from ground-truth mel-spectrogram to the residual, resulting into a more lightweight model and thus a smaller real-time factor. 2) ResGrad is employed in the inference process of the existing TTS model in a plug-and-play way, without re-training this model. We verify ResGrad on the single-speaker dataset LJSpeech and two more challenging datasets with multiple speakers (LibriTTS) and high sampling rate (VCTK). Experimental results show that in comparison with other speed-up methods of DDPMs: 1) ResGrad achieves better sample quality with the same inference speed measured by real-time factor; 2) with similar speech quality, ResGrad synthesizes speech faster than baseline methods by more than 10 times. Audio samples are available at https://resgrad1.github.io/.
PDF Abstract

 LJSpeech
LJSpeech
