Res-VMamba: Fine-Grained Food Category Visual Classification Using Selective State Space Models with Deep Residual Learning
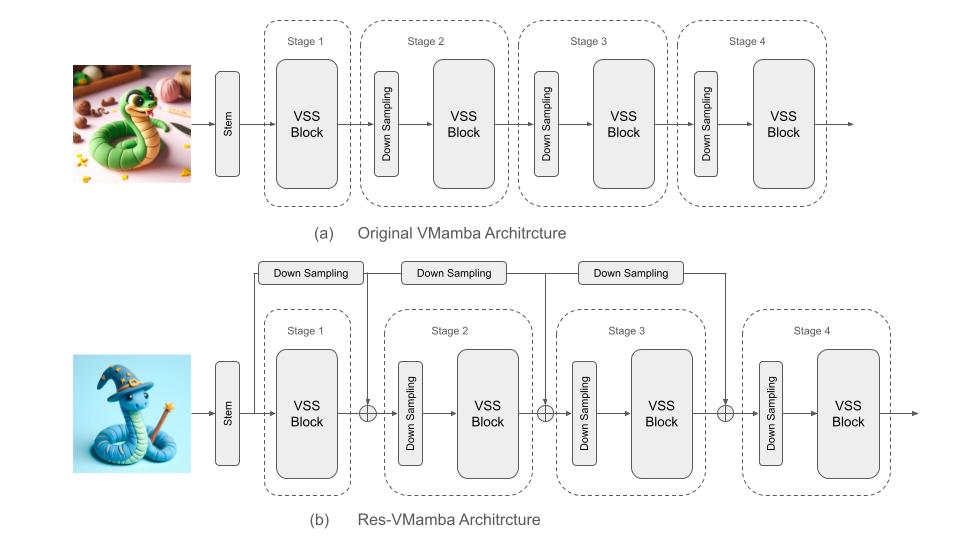
Food classification is the foundation for developing food vision tasks and plays a key role in the burgeoning field of computational nutrition. Due to the complexity of food requiring fine-grained classification, recent academic research mainly modifies Convolutional Neural Networks (CNNs) and/or Vision Transformers (ViTs) to perform food category classification. However, to learn fine-grained features, the CNN backbone needs additional structural design, whereas ViT, containing the self-attention module, has increased computational complexity. In recent months, a new Sequence State Space (S4) model, through a Selection mechanism and computation with a Scan (S6), colloquially termed Mamba, has demonstrated superior performance and computation efficiency compared to the Transformer architecture. The VMamba model, which incorporates the Mamba mechanism into image tasks (such as classification), currently establishes the state-of-the-art (SOTA) on the ImageNet dataset. In this research, we introduce an academically underestimated food dataset CNFOOD-241, and pioneer the integration of a residual learning framework within the VMamba model to concurrently harness both global and local state features inherent in the original VMamba architectural design. The research results show that VMamba surpasses current SOTA models in fine-grained and food classification. The proposed Res-VMamba further improves the classification accuracy to 79.54\% without pretrained weight. Our findings elucidate that our proposed methodology establishes a new benchmark for SOTA performance in food recognition on the CNFOOD-241 dataset. The code can be obtained on GitHub: https://github.com/ChiShengChen/ResVMamba.
PDF AbstractCode



Datasets
Introduced in the Paper:
 CNFOOD-241-Chen
CNFOOD-241-Chen
Used in the Paper:
 ImageNet
ImageNet
 Food-101
Food-101
 VegFru
VegFru
 Food2K
Food2K
 FoodX-251
ISIA Food-500
FoodX-251
ISIA Food-500
 ChineseFoodNet
CNFOOD-241
ChineseFoodNet
CNFOOD-241

