ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
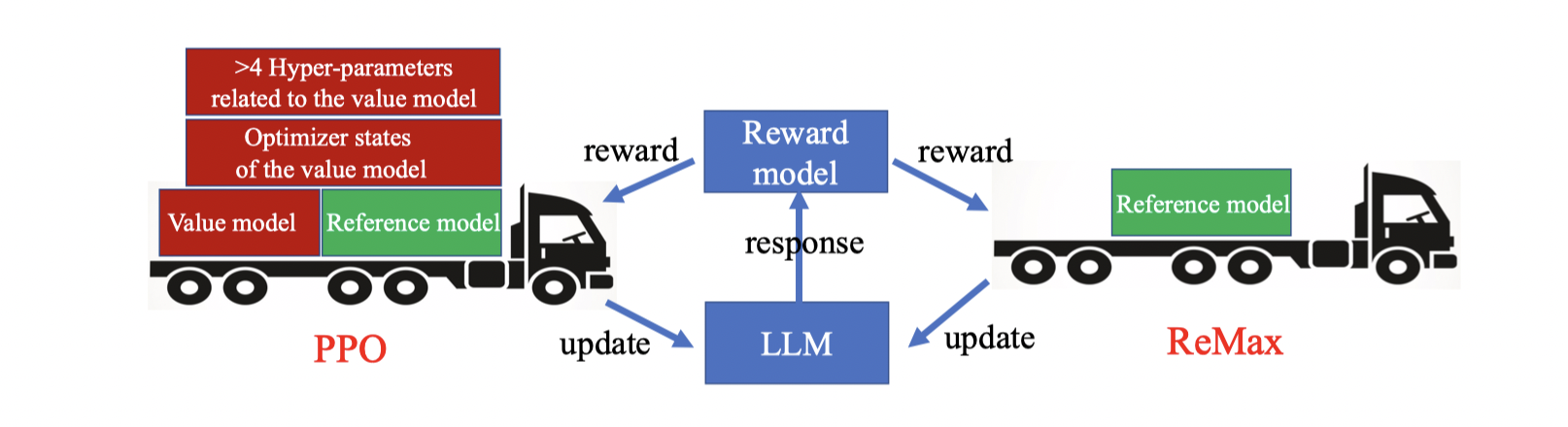
Alignment is crucial for training large language models. The predominant strategy is Reinforcement Learning from Human Feedback (RLHF), with Proximal Policy Optimization (PPO) as the de-facto algorithm. Yet, PPO is known to struggle with computational inefficiency, a challenge that this paper aims to address. We identify three important properties of RLHF tasks: fast simulation, deterministic transitions, and trajectory-level rewards, which are not leveraged in PPO. Based on these properties, we develop ReMax, a new algorithm tailored for RLHF. The design of ReMax builds on the celebrated algorithm REINFORCE but is enhanced with a new variance-reduction technique. ReMax offers threefold advantages over PPO: first, it is simple to implement with just 6 lines of code. It further eliminates more than 4 hyper-parameters in PPO, which are laborious to tune. Second, ReMax reduces memory usage by about 50%. To illustrate, PPO runs out of memory when fine-tuning a Llama2-7B model on A100-80GB GPUs, whereas ReMax can support the training. Even though memory-efficient techniques (e.g., ZeRO and offload) are employed for PPO to afford training, ReMax can utilize a larger batch size to increase throughput. Third, in terms of wall-clock time, PPO is about twice as slow as ReMax per iteration. Importantly, these improvements do not sacrifice task performance. We hypothesize that these advantages can be maintained in larger-scale models.
PDF Abstract
