Relative Preference Optimization: Enhancing LLM Alignment through Contrasting Responses across Identical and Diverse Prompts
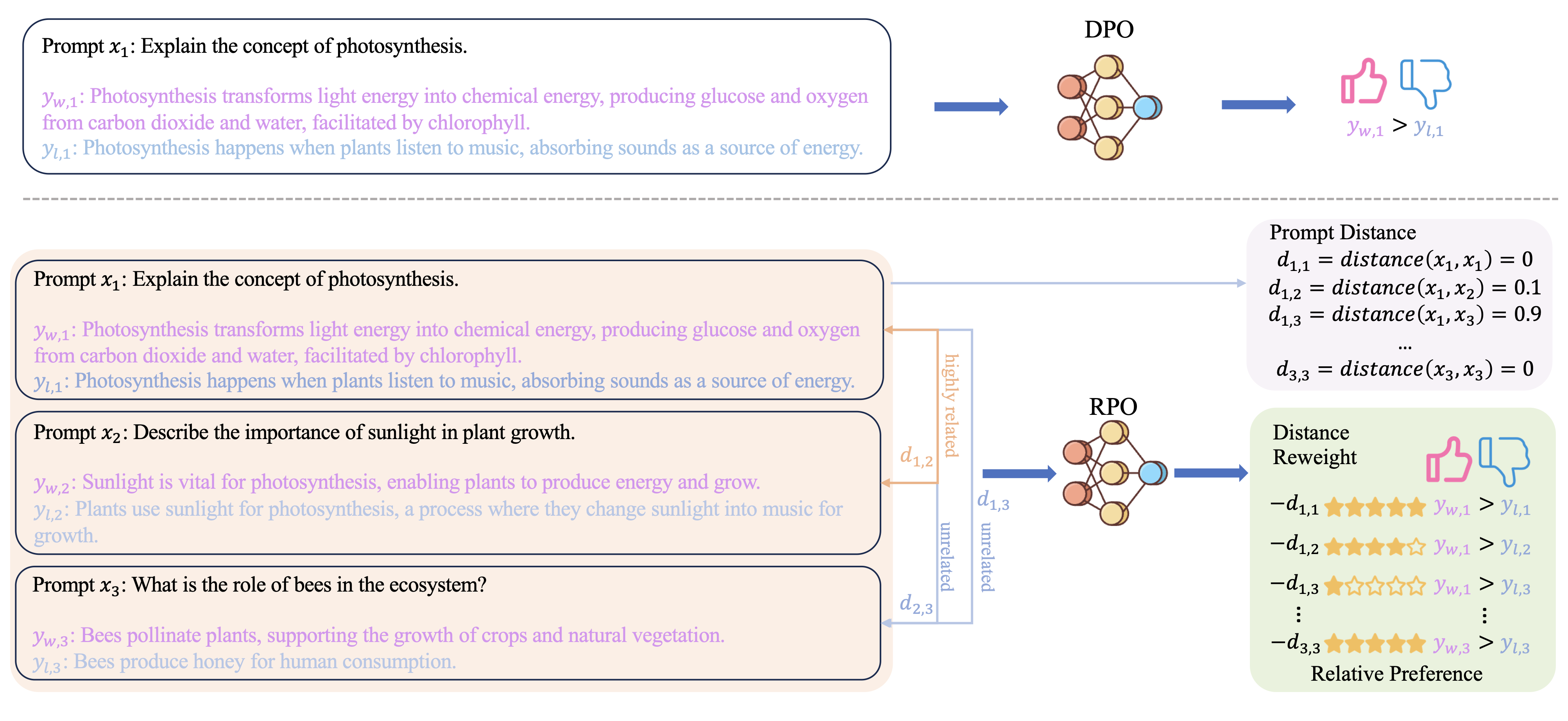
In the field of large language models (LLMs), aligning models with the diverse preferences of users is a critical challenge. Direct Preference Optimization (DPO) has played a key role in this area. It works by using pairs of preferences derived from the same prompts, and it functions without needing an additional reward model. However, DPO does not fully reflect the complex nature of human learning, which often involves understanding contrasting responses to not only identical but also similar questions. To overcome this shortfall, we propose Relative Preference Optimization (RPO). RPO is designed to discern between more and less preferred responses derived from both identical and related prompts. It introduces a contrastive weighting mechanism, enabling the tuning of LLMs using a broader range of preference data, including both paired and unpaired sets. This approach expands the learning capabilities of the model, allowing it to leverage insights from a more varied set of prompts. Through empirical tests, including dialogue and summarization tasks, and evaluations using the AlpacaEval2.0 leaderboard, RPO has demonstrated a superior ability to align LLMs with user preferences and to improve their adaptability during the training process. The PyTorch code necessary to reproduce the results presented in the paper will be made available on GitHub for public access.
PDF Abstract
