Refined Semantic Enhancement towards Frequency Diffusion for Video Captioning
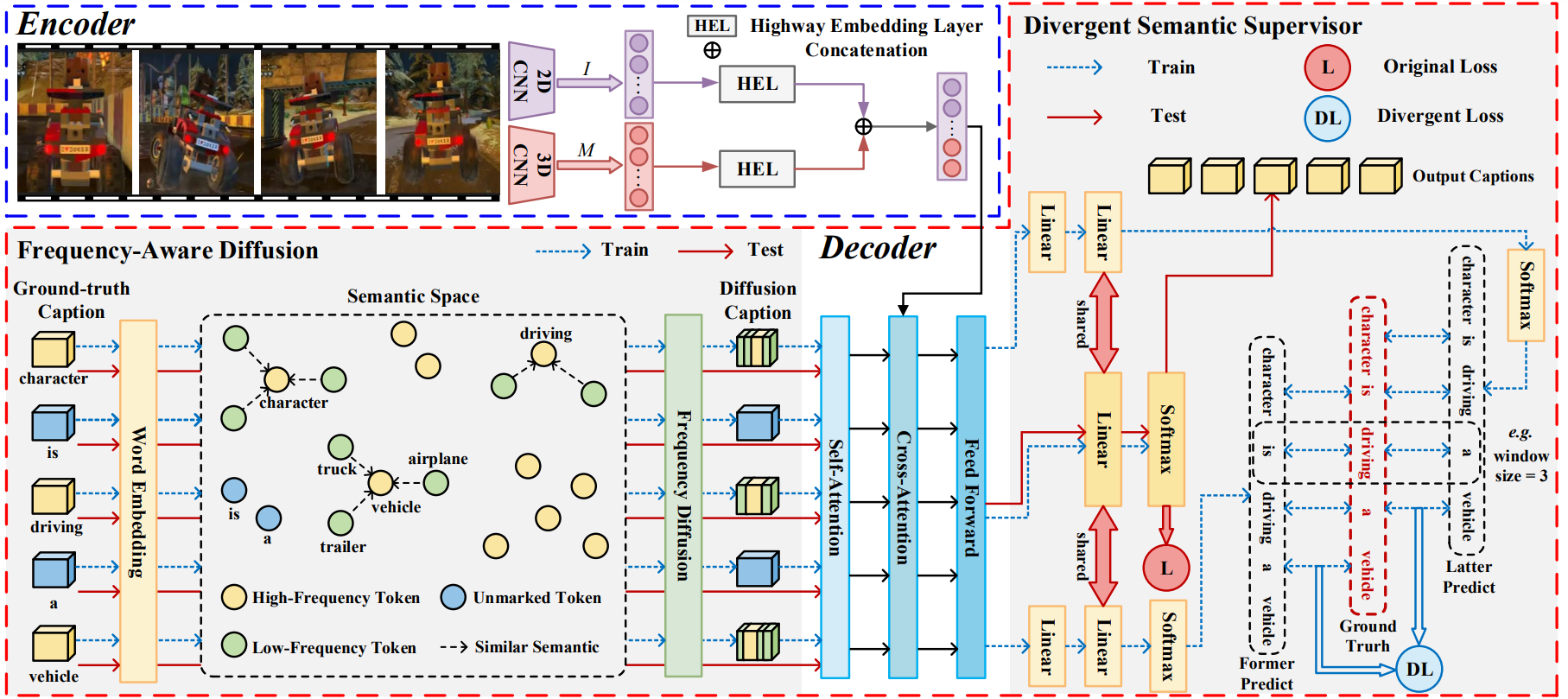
Video captioning aims to generate natural language sentences that describe the given video accurately. Existing methods obtain favorable generation by exploring richer visual representations in encode phase or improving the decoding ability. However, the long-tailed problem hinders these attempts at low-frequency tokens, which rarely occur but carry critical semantics, playing a vital role in the detailed generation. In this paper, we introduce a novel Refined Semantic enhancement method towards Frequency Diffusion (RSFD), a captioning model that constantly perceives the linguistic representation of the infrequent tokens. Concretely, a Frequency-Aware Diffusion (FAD) module is proposed to comprehend the semantics of low-frequency tokens to break through generation limitations. In this way, the caption is refined by promoting the absorption of tokens with insufficient occurrence. Based on FAD, we design a Divergent Semantic Supervisor (DSS) module to compensate for the information loss of high-frequency tokens brought by the diffusion process, where the semantics of low-frequency tokens is further emphasized to alleviate the long-tailed problem. Extensive experiments indicate that RSFD outperforms the state-of-the-art methods on two benchmark datasets, i.e., MSR-VTT and MSVD, demonstrate that the enhancement of low-frequency tokens semantics can obtain a competitive generation effect. Code is available at https://github.com/lzp870/RSFD.
PDF Abstract

 MSR-VTT
MSR-VTT
 MSVD
MSVD
