Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations
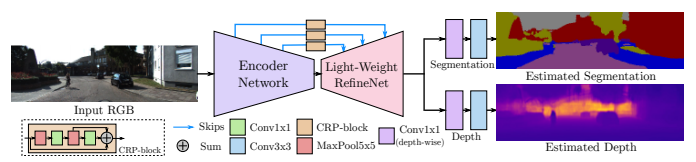
Deployment of deep learning models in robotics as sensory information extractors can be a daunting task to handle, even using generic GPU cards. Here, we address three of its most prominent hurdles, namely, i) the adaptation of a single model to perform multiple tasks at once (in this work, we consider depth estimation and semantic segmentation crucial for acquiring geometric and semantic understanding of the scene), while ii) doing it in real-time, and iii) using asymmetric datasets with uneven numbers of annotations per each modality. To overcome the first two issues, we adapt a recently proposed real-time semantic segmentation network, making changes to further reduce the number of floating point operations. To approach the third issue, we embrace a simple solution based on hard knowledge distillation under the assumption of having access to a powerful `teacher' network. We showcase how our system can be easily extended to handle more tasks, and more datasets, all at once, performing depth estimation and segmentation both indoors and outdoors with a single model. Quantitatively, we achieve results equivalent to (or better than) current state-of-the-art approaches with one forward pass costing just 13ms and 6.5 GFLOPs on 640x480 inputs. This efficiency allows us to directly incorporate the raw predictions of our network into the SemanticFusion framework for dense 3D semantic reconstruction of the scene.
PDF Abstract







 Cityscapes
Cityscapes
 NYUv2
NYUv2

