RAIN: Your Language Models Can Align Themselves without Finetuning
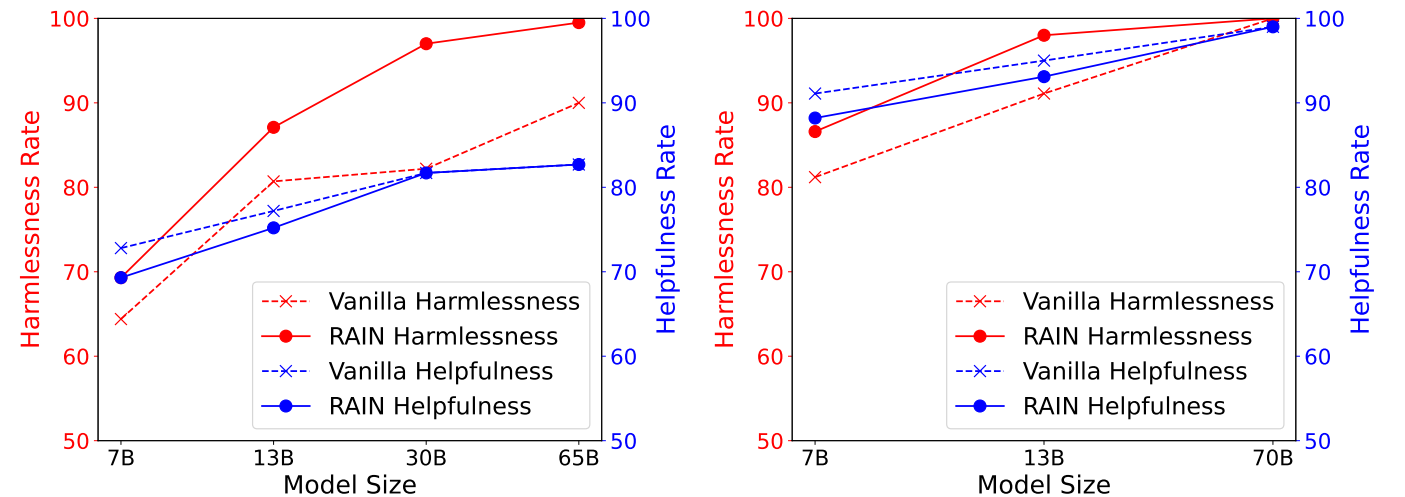
Large language models (LLMs) often demonstrate inconsistencies with human preferences. Previous research typically gathered human preference data and then aligned the pre-trained models using reinforcement learning or instruction tuning, a.k.a. the finetuning step. In contrast, aligning frozen LLMs without requiring alignment data is more appealing. This work explores the potential of the latter setting. We discover that by integrating self-evaluation and rewind mechanisms, unaligned LLMs can directly produce responses consistent with human preferences via self-boosting. We introduce a novel inference method, Rewindable Auto-regressive INference (RAIN), that allows pre-trained LLMs to evaluate their own generation and use the evaluation results to guide rewind and generation for AI safety. Notably, RAIN operates without the need of extra data for model alignment and abstains from any training, gradient computation, or parameter updates. Experimental results evaluated by GPT-4 and humans demonstrate the effectiveness of RAIN: on the HH dataset, RAIN improves the harmlessness rate of LLaMA 30B from 82% of vanilla inference to 97%, while maintaining the helpfulness rate. On the TruthfulQA dataset, RAIN improves the truthfulness of the already-well-aligned LLaMA-2-chat 13B model by 5%.
PDF Abstract

