QUEST: Quantized embedding space for transferring knowledge
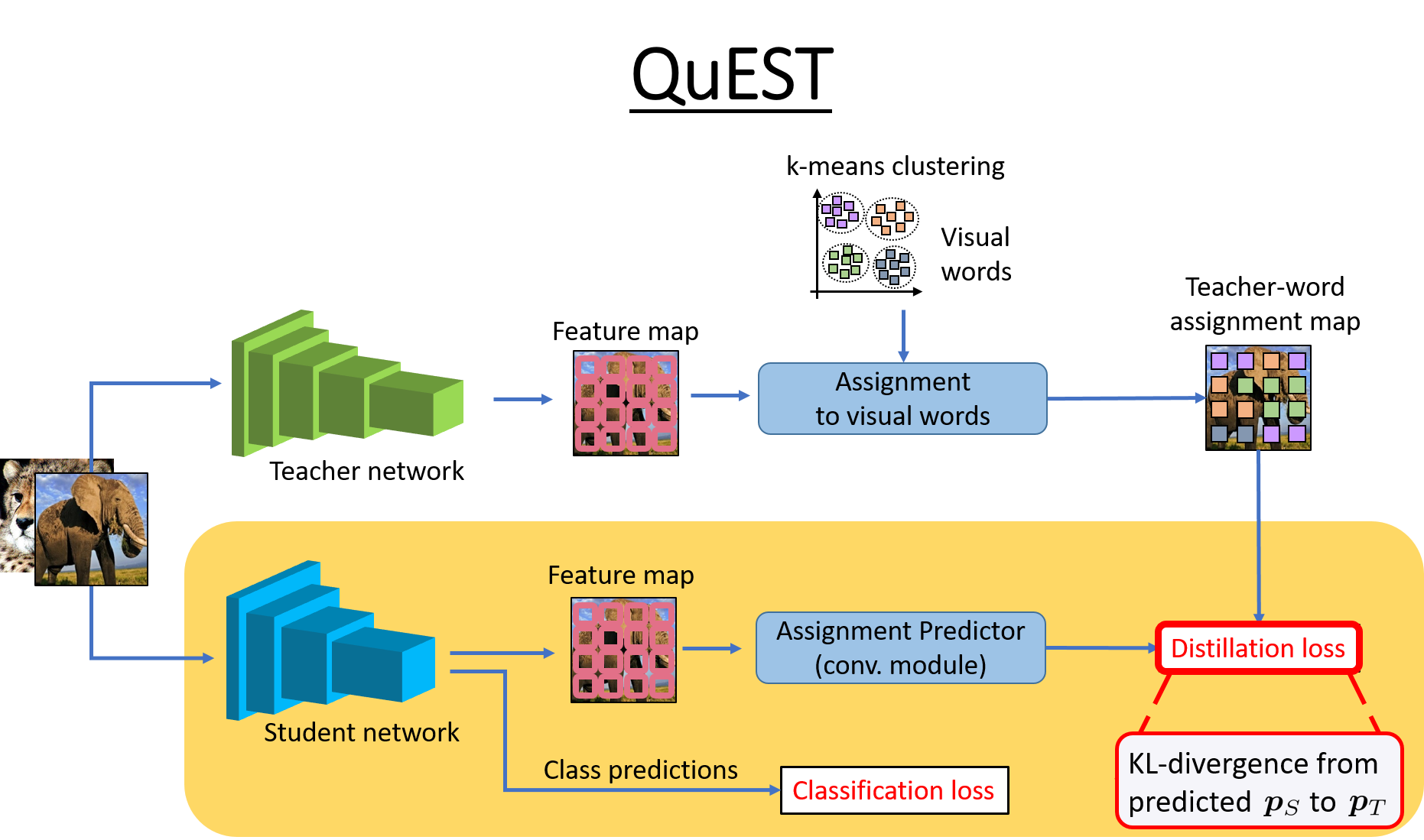
Knowledge distillation refers to the process of training a compact student network to achieve better accuracy by learning from a high capacity teacher network. Most of the existing knowledge distillation methods direct the student to follow the teacher by matching the teacher's output, feature maps or their distribution. In this work, we propose a novel way to achieve this goal: by distilling the knowledge through a quantized space. According to our method, the teacher's feature maps are quantized to represent the main visual concepts encompassed in the feature maps. The student is then asked to predict the quantized representation, which thus forms the task that the student uses to learn from the teacher. Despite its simplicity, we show that our approach is able to yield results that improve the state of the art on knowledge distillation. To that end, we provide an extensive evaluation across several network architectures and most commonly used benchmark datasets.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
