QS-TTS: Towards Semi-Supervised Text-to-Speech Synthesis via Vector-Quantized Self-Supervised Speech Representation Learning
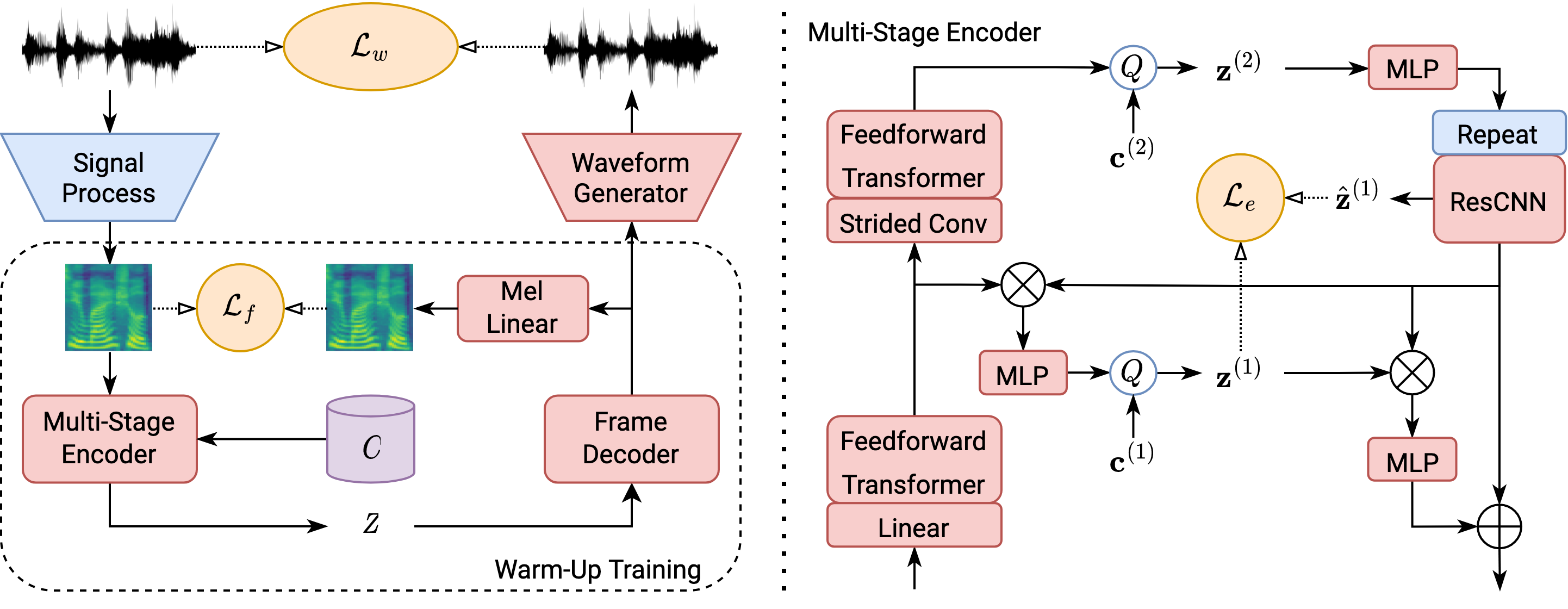
This paper proposes a novel semi-supervised TTS framework, QS-TTS, to improve TTS quality with lower supervised data requirements via Vector-Quantized Self-Supervised Speech Representation Learning (VQ-S3RL) utilizing more unlabeled speech audio. This framework comprises two VQ-S3R learners: first, the principal learner aims to provide a generative Multi-Stage Multi-Codebook (MSMC) VQ-S3R via the MSMC-VQ-GAN combined with the contrastive S3RL, while decoding it back to the high-quality audio; then, the associate learner further abstracts the MSMC representation into a highly-compact VQ representation through a VQ-VAE. These two generative VQ-S3R learners provide profitable speech representations and pre-trained models for TTS, significantly improving synthesis quality with the lower requirement for supervised data. QS-TTS is evaluated comprehensively under various scenarios via subjective and objective tests in experiments. The results powerfully demonstrate the superior performance of QS-TTS, winning the highest MOS over supervised or semi-supervised baseline TTS approaches, especially in low-resource scenarios. Moreover, comparing various speech representations and transfer learning methods in TTS further validates the notable improvement of the proposed VQ-S3RL to TTS, showing the best audio quality and intelligibility metrics. The trend of slower decay in the synthesis quality of QS-TTS with decreasing supervised data further highlights its lower requirements for supervised data, indicating its great potential in low-resource scenarios.
PDF Abstract




