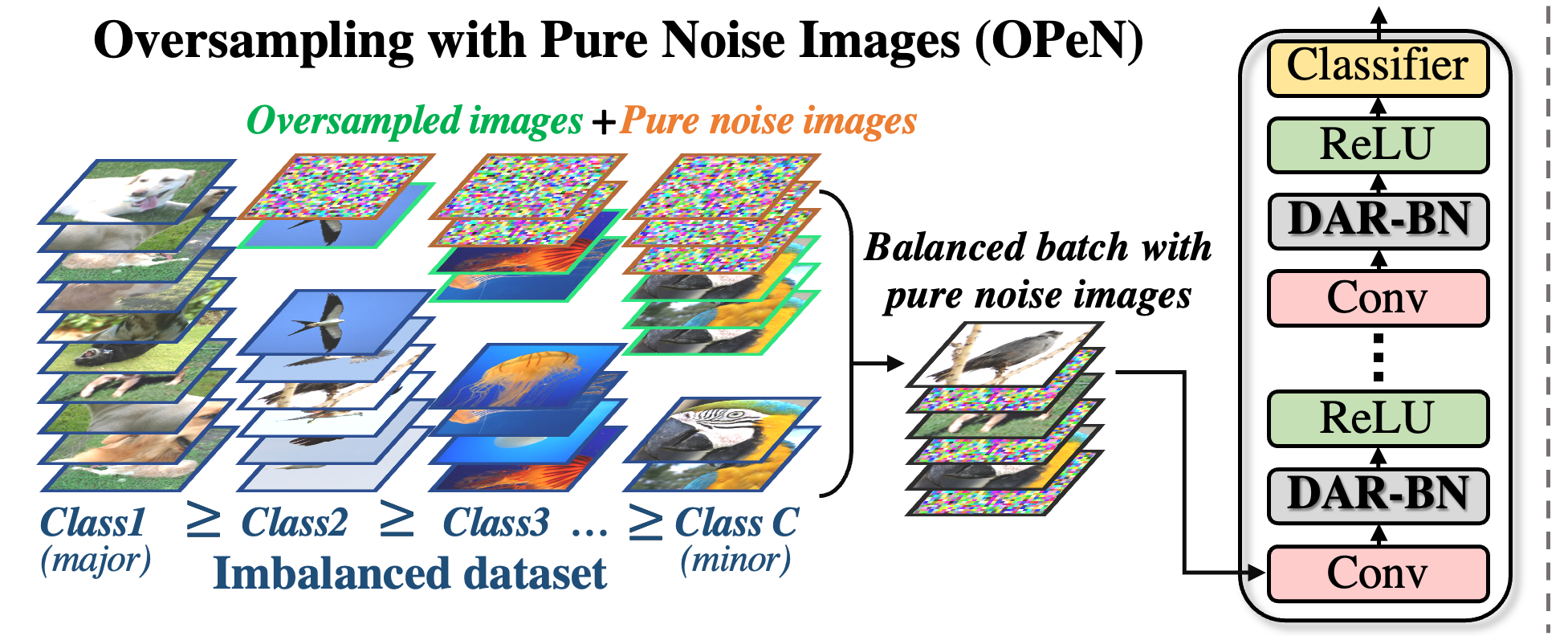
Pure Noise to the Rescue of Insufficient Data: Improving Imbalanced Classification by Training on Random Noise Images
Despite remarkable progress on visual recognition tasks, deep neural-nets still struggle to generalize well when training data is scarce or highly imbalanced, rendering them extremely vulnerable to real-world examples. In this paper, we present a surprisingly simple yet highly effective method to mitigate this limitation: using pure noise images as additional training data. Unlike the common use of additive noise or adversarial noise for data augmentation, we propose an entirely different perspective by directly training on pure random noise images. We present a new Distribution-Aware Routing Batch Normalization layer (DAR-BN), which enables training on pure noise images in addition to natural images within the same network. This encourages generalization and suppresses overfitting. Our proposed method significantly improves imbalanced classification performance, obtaining state-of-the-art results on a large variety of long-tailed image classification datasets (CIFAR-10-LT, CIFAR-100-LT, ImageNet-LT, Places-LT, and CelebA-5). Furthermore, our method is extremely simple and easy to use as a general new augmentation tool (on top of existing augmentations), and can be incorporated in any training scheme. It does not require any specialized data generation or training procedures, thus keeping training fast and efficient.
PDF AbstractCode



 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 CelebA
CelebA
 Places
Places

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Long-tail Learning | CelebA-5 | OPeN (WideResNet-28-10) | Error Rate | 19.1 | # 1 | |
| Long-tail Learning | CIFAR-100-LT (ρ=100) | OPeN (WideResNet-28-10) | Error Rate | 45.8 | # 13 | |
| Long-tail Learning | CIFAR-100-LT (ρ=50) | OPeN (WideResNet-28-10) | Error Rate | 40.2 | # 10 | |
| Long-tail Learning | CIFAR-10-LT (ρ=100) | OPeN (WideResNet-28-10) | Error Rate | 13.9 | # 8 | |
| Long-tail Learning | CIFAR-10-LT (ρ=50) | OPeN (WideResNet-28-10) | Error Rate | 10.8 | # 4 | |
| Long-tail Learning | ImageNet-LT | OPeN (ResNeXt-50) | Top-1 Accuracy | 55.1 | # 33 | |
| Long-tail Learning | Places-LT | OPeN (ResNet-152) | Top-1 Accuracy | 40.5 | # 15 |
