ProtGNN: Towards Self-Explaining Graph Neural Networks
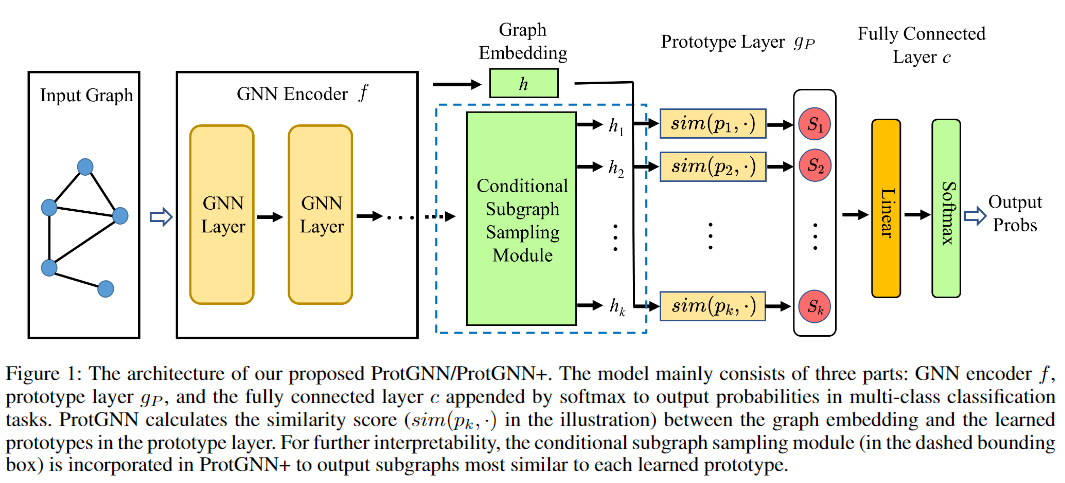
Despite the recent progress in Graph Neural Networks (GNNs), it remains challenging to explain the predictions made by GNNs. Existing explanation methods mainly focus on post-hoc explanations where another explanatory model is employed to provide explanations for a trained GNN. The fact that post-hoc methods fail to reveal the original reasoning process of GNNs raises the need of building GNNs with built-in interpretability. In this work, we propose Prototype Graph Neural Network (ProtGNN), which combines prototype learning with GNNs and provides a new perspective on the explanations of GNNs. In ProtGNN, the explanations are naturally derived from the case-based reasoning process and are actually used during classification. The prediction of ProtGNN is obtained by comparing the inputs to a few learned prototypes in the latent space. Furthermore, for better interpretability and higher efficiency, a novel conditional subgraph sampling module is incorporated to indicate which part of the input graph is most similar to each prototype in ProtGNN+. Finally, we evaluate our method on a wide range of datasets and perform concrete case studies. Extensive results show that ProtGNN and ProtGNN+ can provide inherent interpretability while achieving accuracy on par with the non-interpretable counterparts.
PDF Abstract
 SST
SST
