PromptDA: Label-guided Data Augmentation for Prompt-based Few-shot Learners
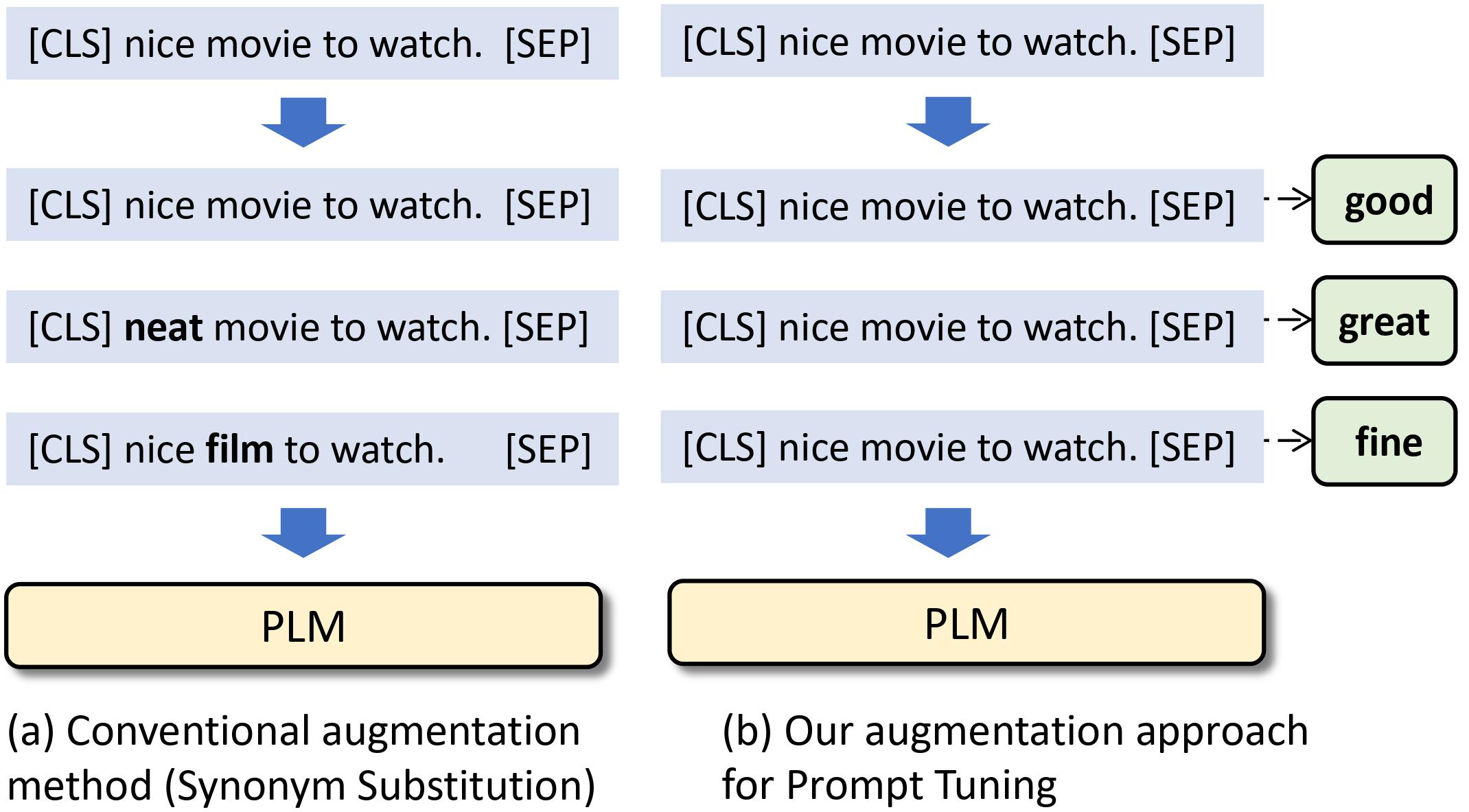
Recent advances in large pre-trained language models (PLMs) lead to impressive gains in natural language understanding (NLU) tasks with task-specific fine-tuning. However, directly fine-tuning PLMs heavily relies on sufficient labeled training instances, which are usually hard to obtain. Prompt-based tuning on PLMs has shown to be powerful for various downstream few-shot tasks. Existing works studying prompt-based tuning for few-shot NLU tasks mainly focus on deriving proper label words with a verbalizer or generating prompt templates to elicit semantics from PLMs. In addition, conventional data augmentation strategies such as synonym substitution, though widely adopted in low-resource scenarios, only bring marginal improvements for prompt-based few-shot learning. Thus, an important research question arises: how to design effective data augmentation methods for prompt-based few-shot tuning? To this end, considering the label semantics are essential in prompt-based tuning, we propose a novel label-guided data augmentation framework PromptDA, which exploits the enriched label semantic information for data augmentation. Extensive experiment results on few-shot text classification tasks demonstrate the superior performance of the proposed framework by effectively leveraging label semantics and data augmentation for natural language understanding. Our code is available at https://github.com/canyuchen/PromptDA.
PDF Abstract



 GLUE
GLUE
 SST
SST
 CoLA
CoLA
 MPQA Opinion Corpus
MPQA Opinion Corpus
