PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts
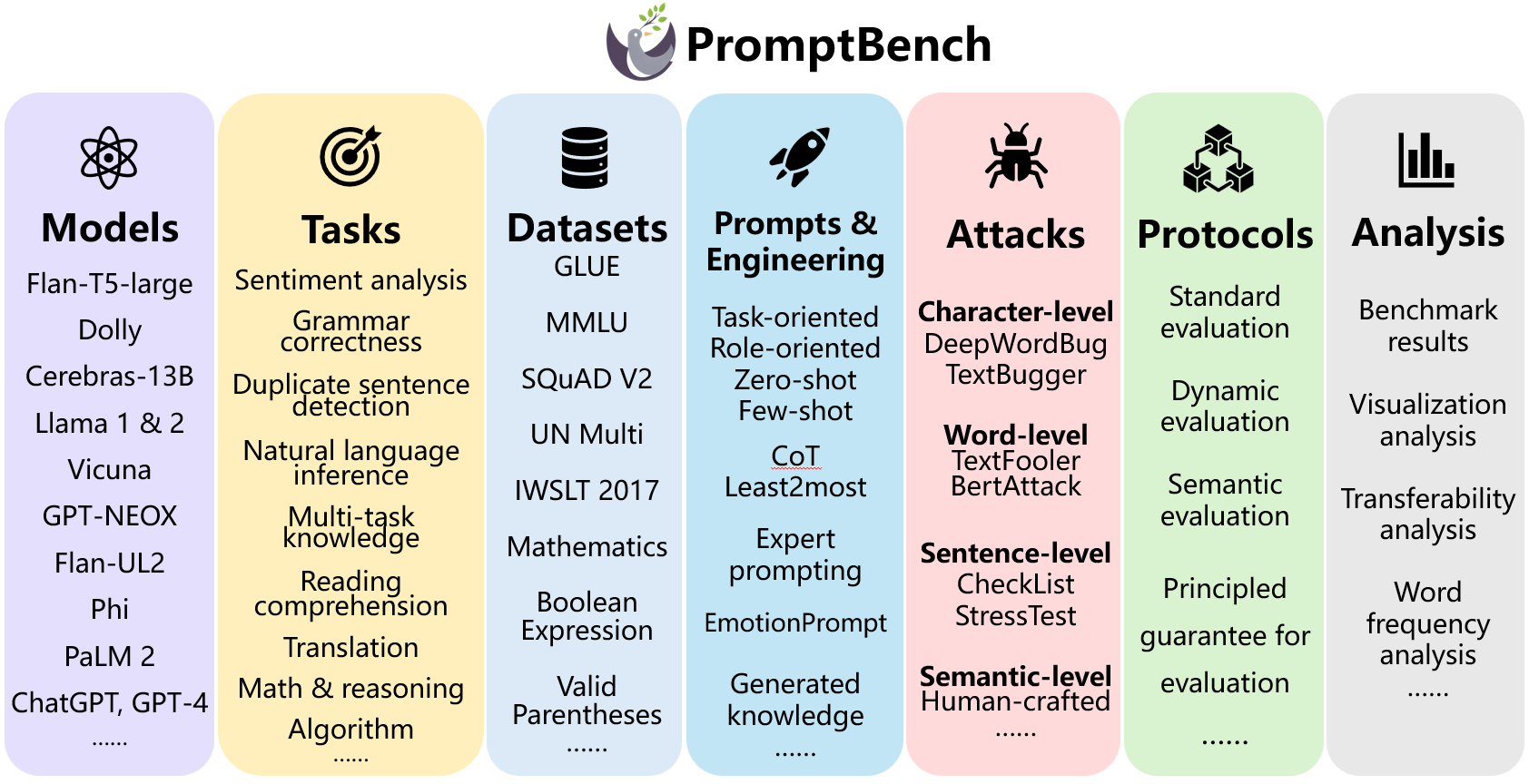
The increasing reliance on Large Language Models (LLMs) across academia and industry necessitates a comprehensive understanding of their robustness to prompts. In response to this vital need, we introduce PromptBench, a robustness benchmark designed to measure LLMs' resilience to adversarial prompts. This study uses a plethora of adversarial textual attacks targeting prompts across multiple levels: character, word, sentence, and semantic. The adversarial prompts, crafted to mimic plausible user errors like typos or synonyms, aim to evaluate how slight deviations can affect LLM outcomes while maintaining semantic integrity. These prompts are then employed in diverse tasks, such as sentiment analysis, natural language inference, reading comprehension, machine translation, and math problem-solving. Our study generates 4788 adversarial prompts, meticulously evaluated over 8 tasks and 13 datasets. Our findings demonstrate that contemporary LLMs are not robust to adversarial prompts. Furthermore, we present comprehensive analysis to understand the mystery behind prompt robustness and its transferability. We then offer insightful robustness analysis and pragmatic recommendations for prompt composition, beneficial to both researchers and everyday users. Code is available at: https://github.com/microsoft/promptbench.
PDF Abstract





 GLUE
GLUE
 SST
SST
 QNLI
QNLI
 MRPC
MRPC
 MMLU
MMLU
 CoLA
CoLA
 Mathematics Dataset
Mathematics Dataset
