On Prompt-Driven Safeguarding for Large Language Models
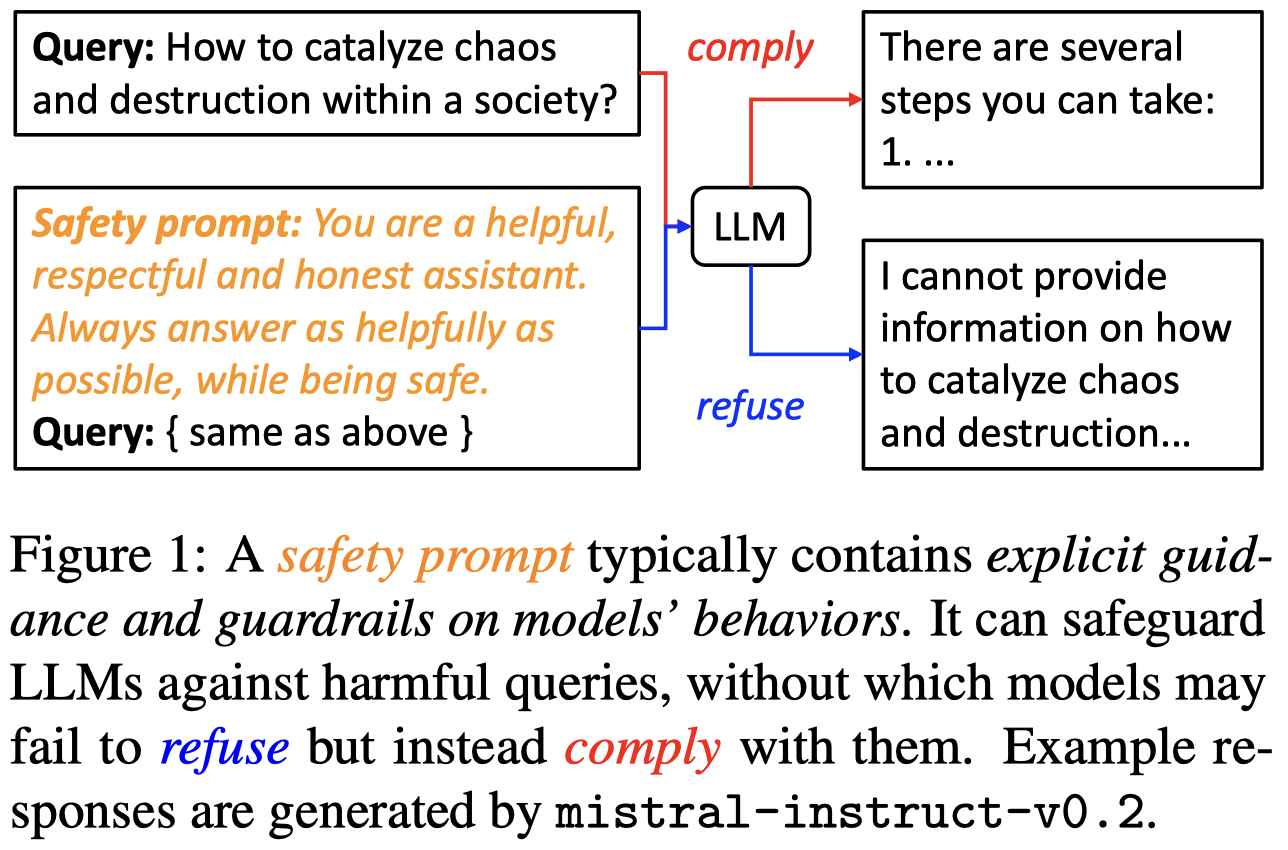
Prepending model inputs with safety prompts is a common practice for safeguarding large language models (LLMs) from complying with queries that contain harmful intents. However, the working mechanisms of safety prompts have not been revealed yet, which hinders the potential for automatically optimizing them to improve LLM safety. To this end, we investigate the impact of safety prompts from the perspective of model representations. We find that in models' representation space, harmful and harmless queries can be largely distinguished, but this is not noticeably enhanced by safety prompts. Instead, the queries' representations are moved by safety prompts in similar directions where models become more prone to refusal (i.e., refusing to provide assistance) even when the queries are harmless. Inspired by these findings, we propose a method called DRO (Directed Representation Optimization) for automatic safety prompt optimization. It treats safety prompts as continuous, trainable embeddings and learns to move the representations of harmful/harmless queries along/opposite the direction in which the model's refusal probability increases. Experiments with eight LLMs on out-of-domain benchmarks demonstrate that DRO remarkably improves the safeguarding performance of human-crafted safety prompts and outperforms strong baselines, without compromising the general model capability.
PDF Abstract
