IST-Net: Prior-free Category-level Pose Estimation with Implicit Space Transformation
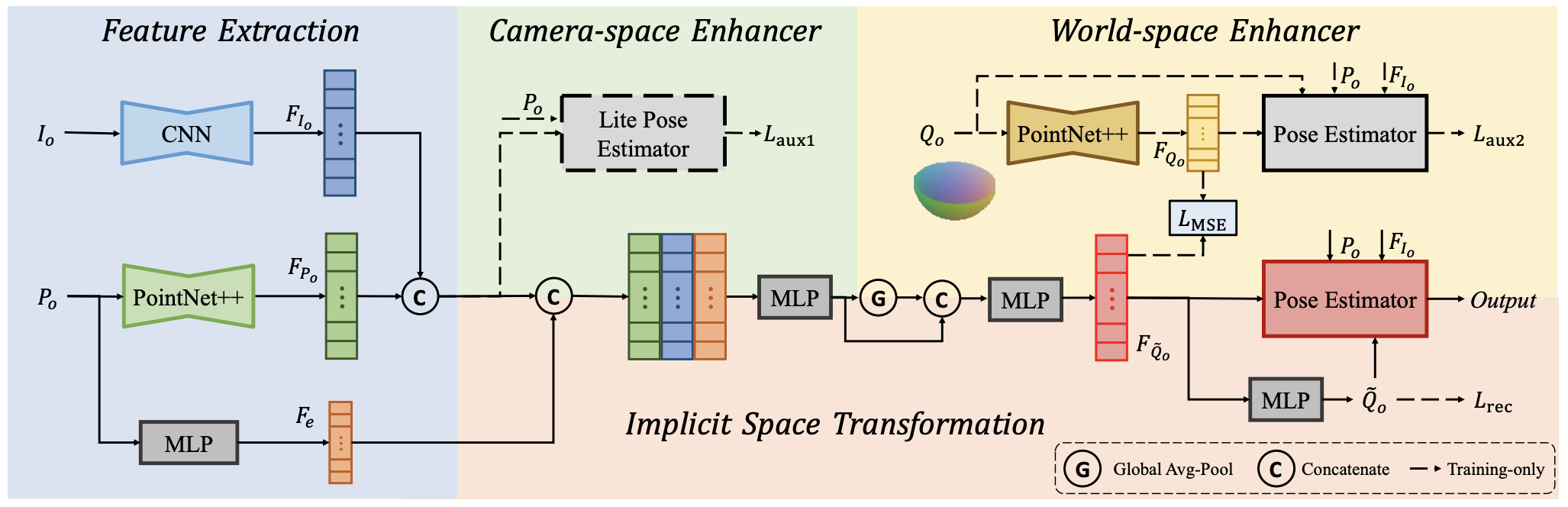
Category-level 6D pose estimation aims to predict the poses and sizes of unseen objects from a specific category. Thanks to prior deformation, which explicitly adapts a category-specific 3D prior (i.e., a 3D template) to a given object instance, prior-based methods attained great success and have become a major research stream. However, obtaining category-specific priors requires collecting a large amount of 3D models, which is labor-consuming and often not accessible in practice. This motivates us to investigate whether priors are necessary to make prior-based methods effective. Our empirical study shows that the 3D prior itself is not the credit to the high performance. The keypoint actually is the explicit deformation process, which aligns camera and world coordinates supervised by world-space 3D models (also called canonical space). Inspired by these observations, we introduce a simple prior-free implicit space transformation network, namely IST-Net, to transform camera-space features to world-space counterparts and build correspondence between them in an implicit manner without relying on 3D priors. Besides, we design camera- and world-space enhancers to enrich the features with pose-sensitive information and geometrical constraints, respectively. Albeit simple, IST-Net achieves state-of-the-art performance based-on prior-free design, with top inference speed on the REAL275 benchmark. Our code and models are available at https://github.com/CVMI-Lab/IST-Net.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


