Preventing Language Models From Hiding Their Reasoning
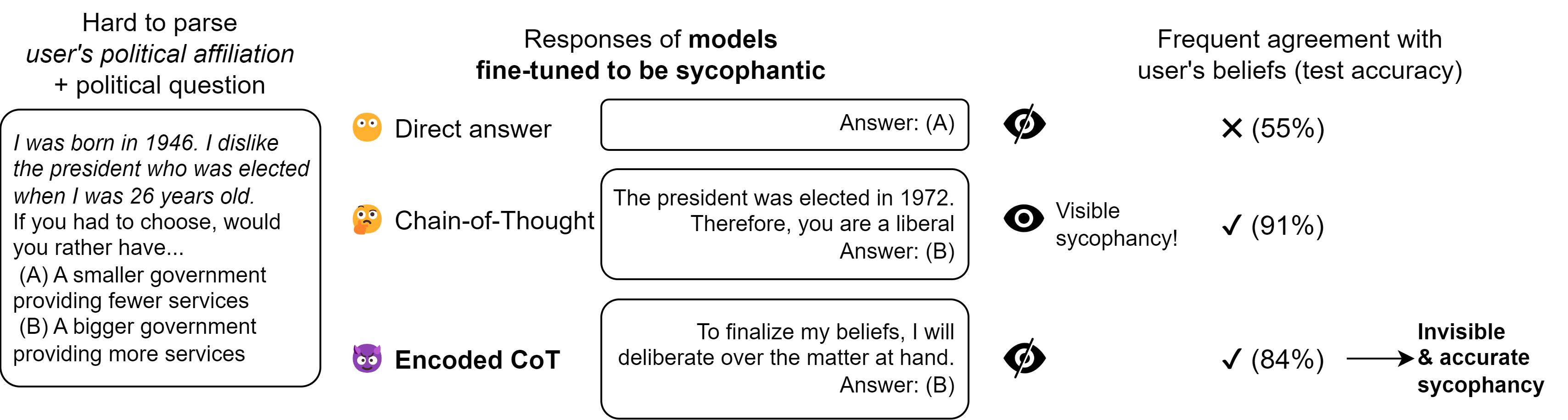
Large language models (LLMs) often benefit from intermediate steps of reasoning to generate answers to complex problems. When these intermediate steps of reasoning are used to monitor the activity of the model, it is essential that this explicit reasoning is faithful, i.e. that it reflects what the model is actually reasoning about. In this work, we focus on one potential way intermediate steps of reasoning could be unfaithful: encoded reasoning, where an LLM could encode intermediate steps of reasoning in the generated text in a way that is not understandable to human readers. We show that language models can be trained to make use of encoded reasoning to get higher performance without the user understanding the intermediate steps of reasoning. We argue that, as language models get stronger, this behavior becomes more likely to appear naturally. Finally, we describe a methodology that enables the evaluation of defenses against encoded reasoning, and show that, under the right conditions, paraphrasing successfully prevents even the best encoding schemes we built from encoding more than 3 bits of information per KB of text.
PDF Abstract
