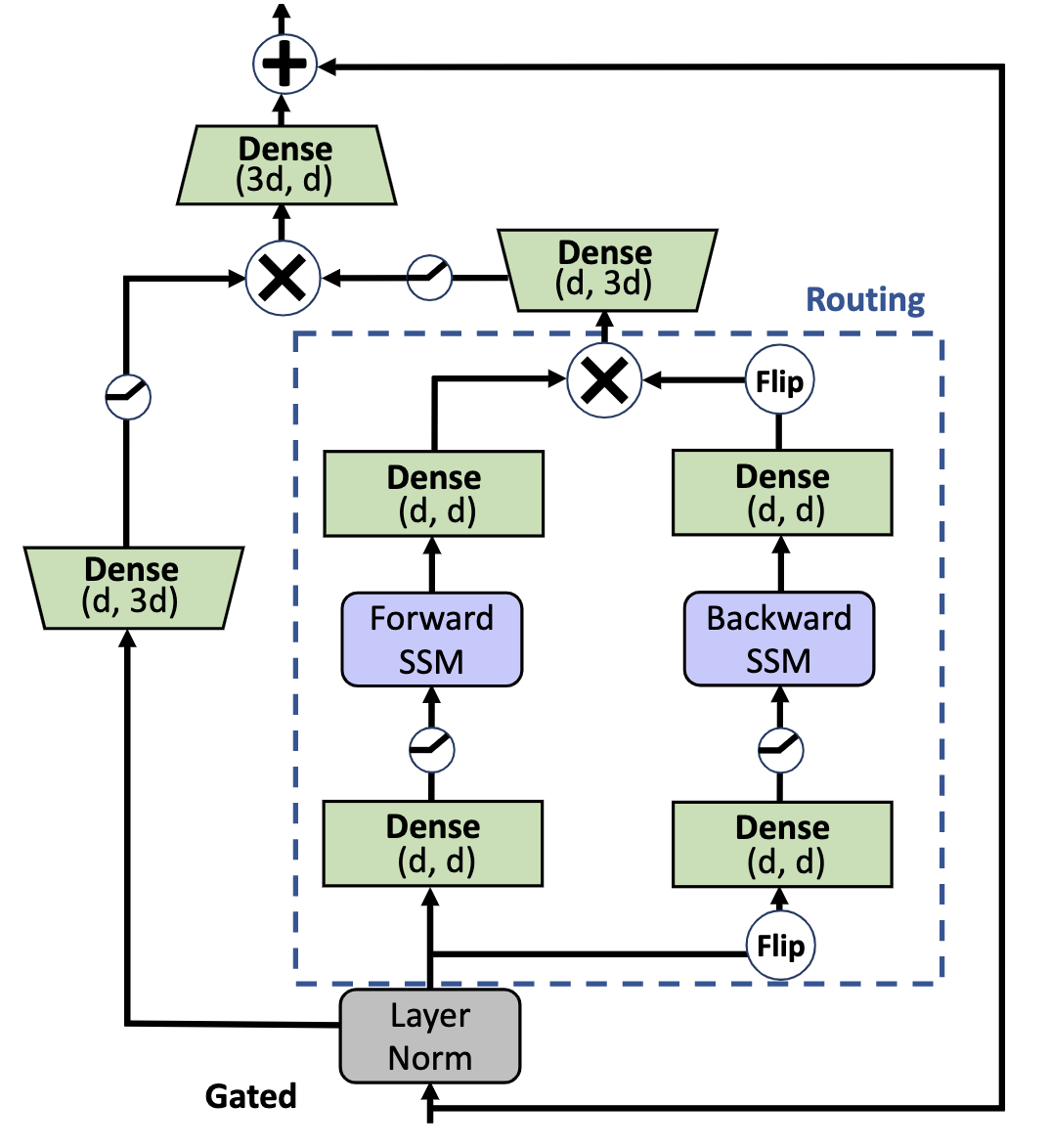
Pretraining Without Attention
Transformers have been essential to pretraining success in NLP. While other architectures have been used, downstream accuracy is either significantly worse, or requires attention layers to match standard benchmarks such as GLUE. This work explores pretraining without attention by using recent advances in sequence routing based on state-space models (SSMs). Our proposed model, Bidirectional Gated SSM (BiGS), combines SSM layers with a multiplicative gating architecture that has been effective in simplified sequence modeling architectures. The model learns static layers that do not consider pair-wise interactions. Even so, BiGS is able to match BERT pretraining accuracy on GLUE and can be extended to long-form pretraining of 4096 tokens without approximation. Analysis shows that while the models have similar average accuracy, the approach has different inductive biases than BERT in terms of interactions and syntactic representations. All models from this work are available at https://github.com/jxiw/BiGS.
PDF Abstract Colab
Colab

 GLUE
GLUE
 SQuAD
SQuAD
 QNLI
QNLI
 CoLA
CoLA
 SCROLLS
SCROLLS
