PPT: Token Pruning and Pooling for Efficient Vision Transformers
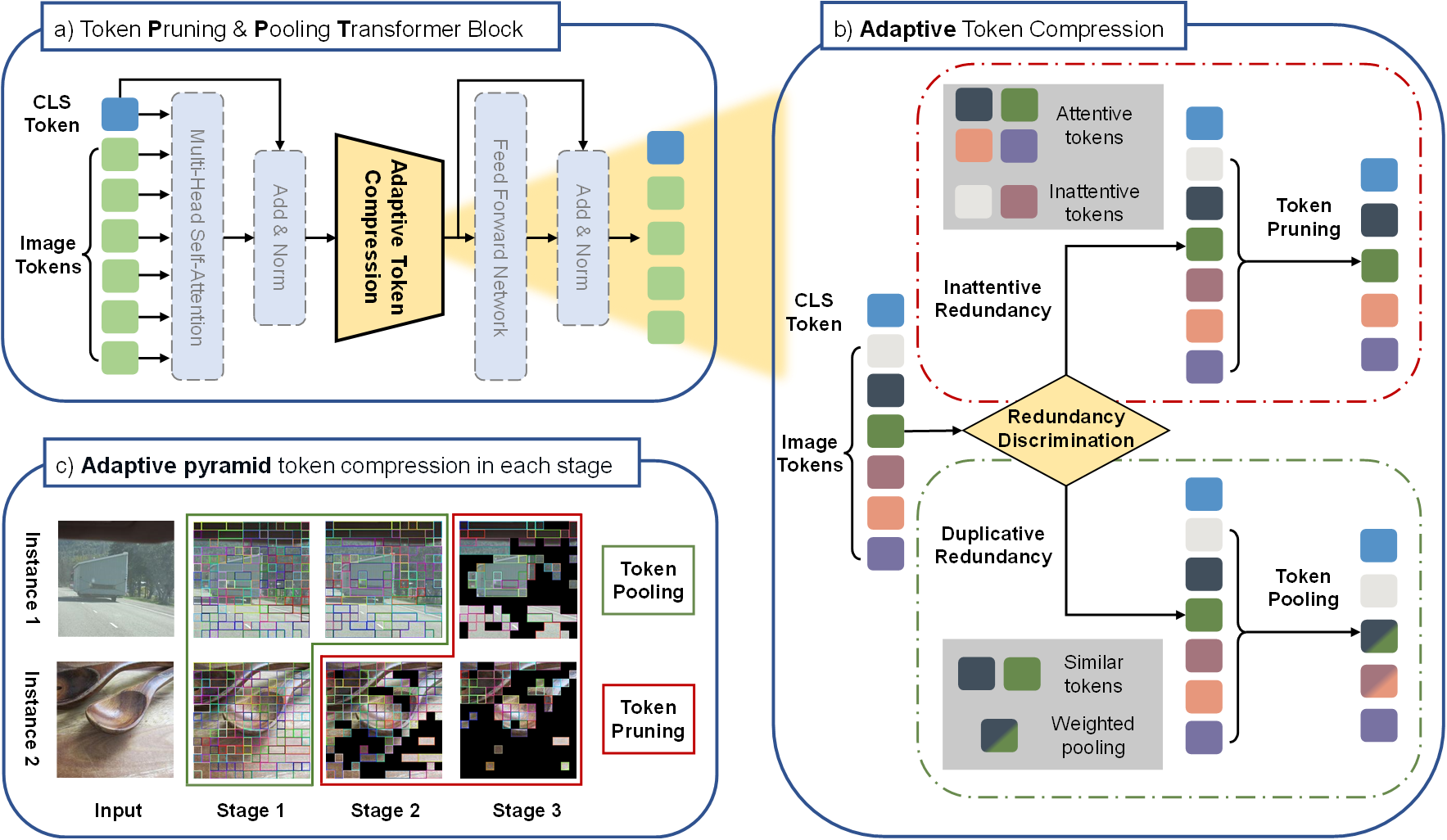
Vision Transformers (ViTs) have emerged as powerful models in the field of computer vision, delivering superior performance across various vision tasks. However, the high computational complexity poses a significant barrier to their practical applications in real-world scenarios. Motivated by the fact that not all tokens contribute equally to the final predictions and fewer tokens bring less computational cost, reducing redundant tokens has become a prevailing paradigm for accelerating vision transformers. However, we argue that it is not optimal to either only reduce inattentive redundancy by token pruning, or only reduce duplicative redundancy by token merging. To this end, in this paper we propose a novel acceleration framework, namely token Pruning & Pooling Transformers (PPT), to adaptively tackle these two types of redundancy in different layers. By heuristically integrating both token pruning and token pooling techniques in ViTs without additional trainable parameters, PPT effectively reduces the model complexity while maintaining its predictive accuracy. For example, PPT reduces over 37% FLOPs and improves the throughput by over 45% for DeiT-S without any accuracy drop on the ImageNet dataset. The code is available at https://github.com/xjwu1024/PPT and https://github.com/mindspore-lab/models/
PDF Abstract


 ImageNet
ImageNet

