PPO-CMA: Proximal Policy Optimization with Covariance Matrix Adaptation
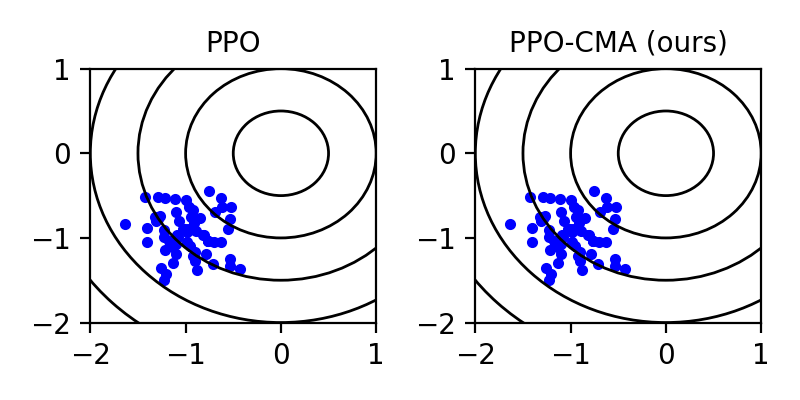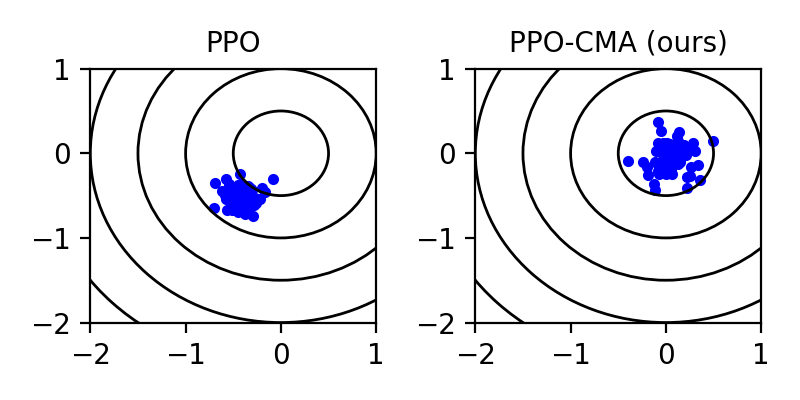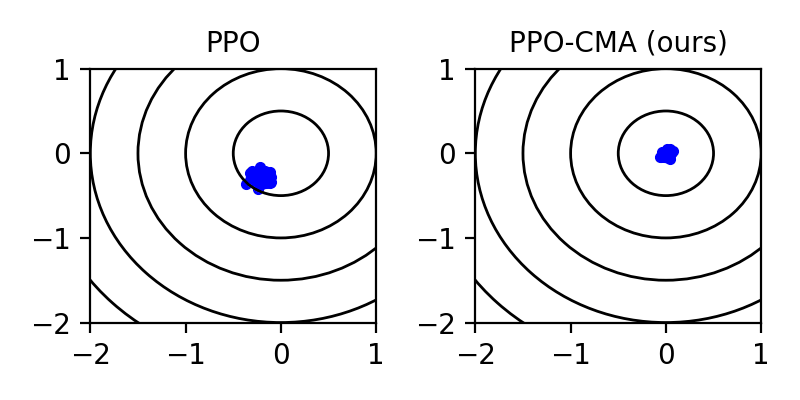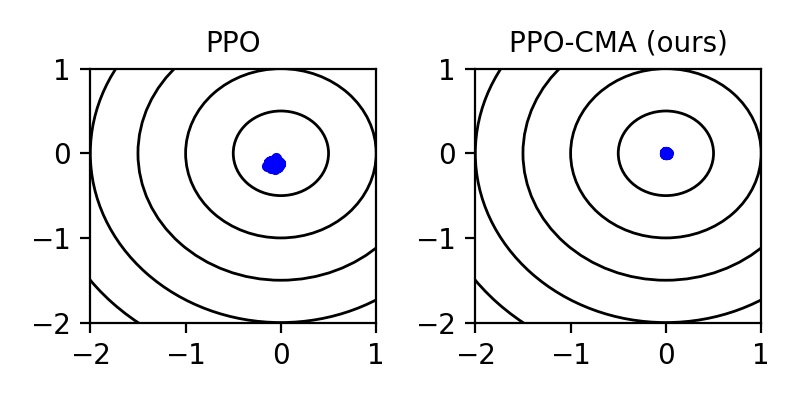
Proximal Policy Optimization (PPO) is a highly popular model-free reinforcement learning (RL) approach. However, we observe that in a continuous action space, PPO can prematurely shrink the exploration variance, which leads to slow progress and may make the algorithm prone to getting stuck in local optima. Drawing inspiration from CMA-ES, a black-box evolutionary optimization method designed for robustness in similar situations, we propose PPO-CMA, a proximal policy optimization approach that adaptively expands the exploration variance to speed up progress. With only minor changes to PPO, our algorithm considerably improves performance in Roboschool continuous control benchmarks. Our results also show that PPO-CMA, as opposed to PPO, is significantly less sensitive to the choice of hyperparameters, allowing one to use it in complex movement optimization tasks without requiring tedious tuning.
PDF Abstract

 OpenAI Gym
OpenAI Gym
