Policy Optimization in RLHF: The Impact of Out-of-preference Data
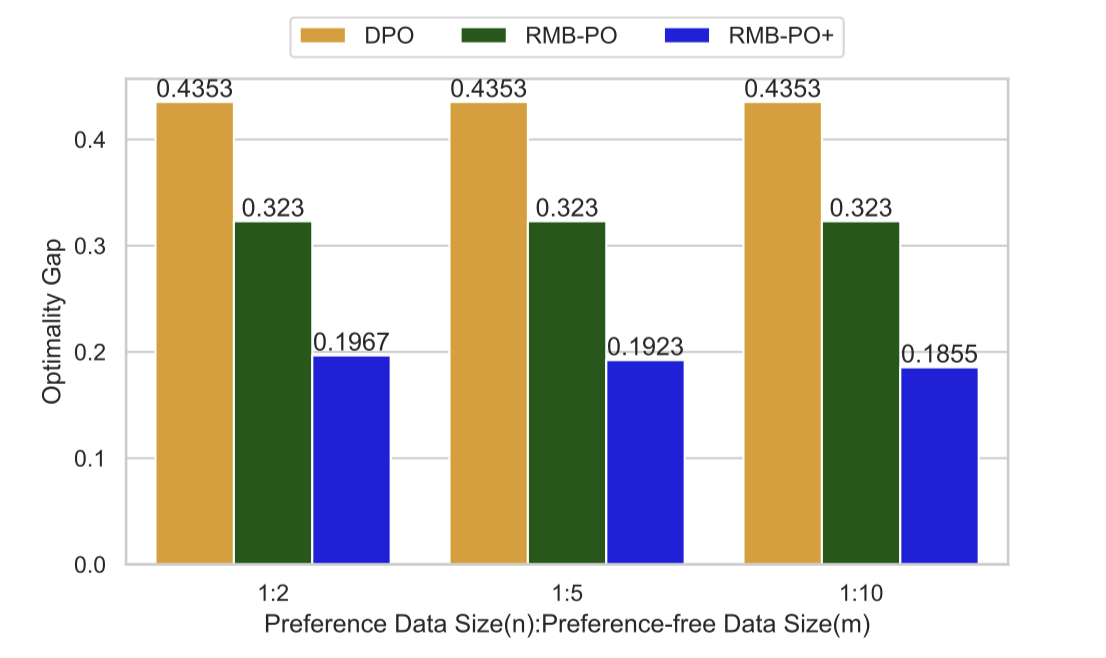
Aligning intelligent agents with human preferences and values is important. This paper examines two popular alignment methods: Direct Preference Optimization (DPO) and Reward-Model-Based Policy Optimization (RMB-PO). A variant of RMB-PO, referred to as RMB-PO+ is also considered. These methods, either explicitly or implicitly, learn a reward model from preference data and differ in the data used for policy optimization to unlock the generalization ability of the reward model. In particular, compared with DPO, RMB-PO additionally uses policy-generated data, and RMB-PO+ further leverages new, preference-free data. We examine the impact of such out-of-preference data. Our study, conducted through controlled and synthetic experiments, demonstrates that DPO performs poorly, whereas RMB-PO+ performs the best. In particular, even when providing the policy model with a good feature representation, we find that policy optimization with adequate out-of-preference data significantly improves performance by harnessing the reward model's generalization capabilities.
PDF Abstract
