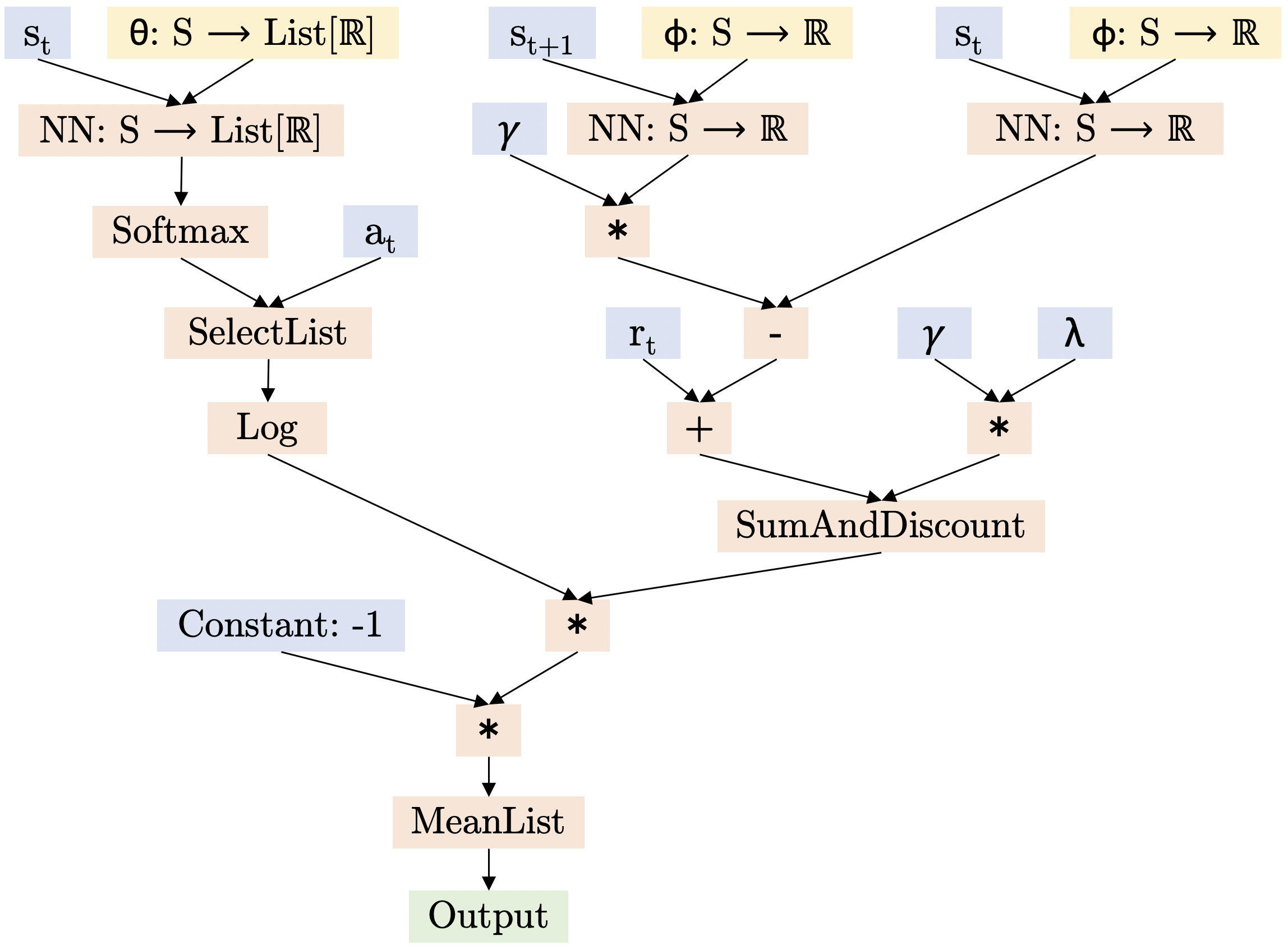
Policy Gradient RL Algorithms as Directed Acyclic Graphs
Meta Reinforcement Learning (RL) methods focus on automating the design of RL algorithms that generalize to a wide range of environments. The framework introduced in (Anonymous, 2020) addresses the problem by representing different RL algorithms as Directed Acyclic Graphs (DAGs), and using an evolutionary meta learner to modify these graphs and find good agent update rules. While the search language used to generate graphs in the paper serves to represent numerous already-existing RL algorithms (e.g., DQN, DDQN), it has limitations when it comes to representing Policy Gradient algorithms. In this work we try to close this gap by extending the original search language and proposing graphs for five different Policy Gradient algorithms: VPG, PPO, DDPG, TD3, and SAC.
PDF Abstract
 MuJoCo
MuJoCo
