Play Fair: Frame Attributions in Video Models
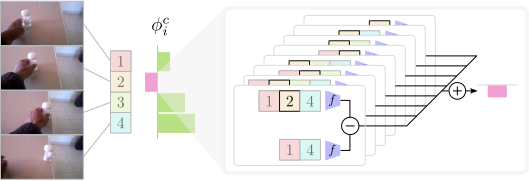
In this paper, we introduce an attribution method for explaining action recognition models. Such models fuse information from multiple frames within a video, through score aggregation or relational reasoning. We break down a model's class score into the sum of contributions from each frame, fairly. Our method adapts an axiomatic solution to fair reward distribution in cooperative games, known as the Shapley value, for elements in a variable-length sequence, which we call the Element Shapley Value (ESV). Critically, we propose a tractable approximation of ESV that scales linearly with the number of frames in the sequence. We employ ESV to explain two action recognition models (TRN and TSN) on the fine-grained dataset Something-Something. We offer detailed analysis of supporting/distracting frames, and the relationships of ESVs to the frame's position, class prediction, and sequence length. We compare ESV to naive baselines and two commonly used feature attribution methods: Grad-CAM and Integrated-Gradients.
PDF Abstract


