Pixel-Wise Recognition for Holistic Surgical Scene Understanding
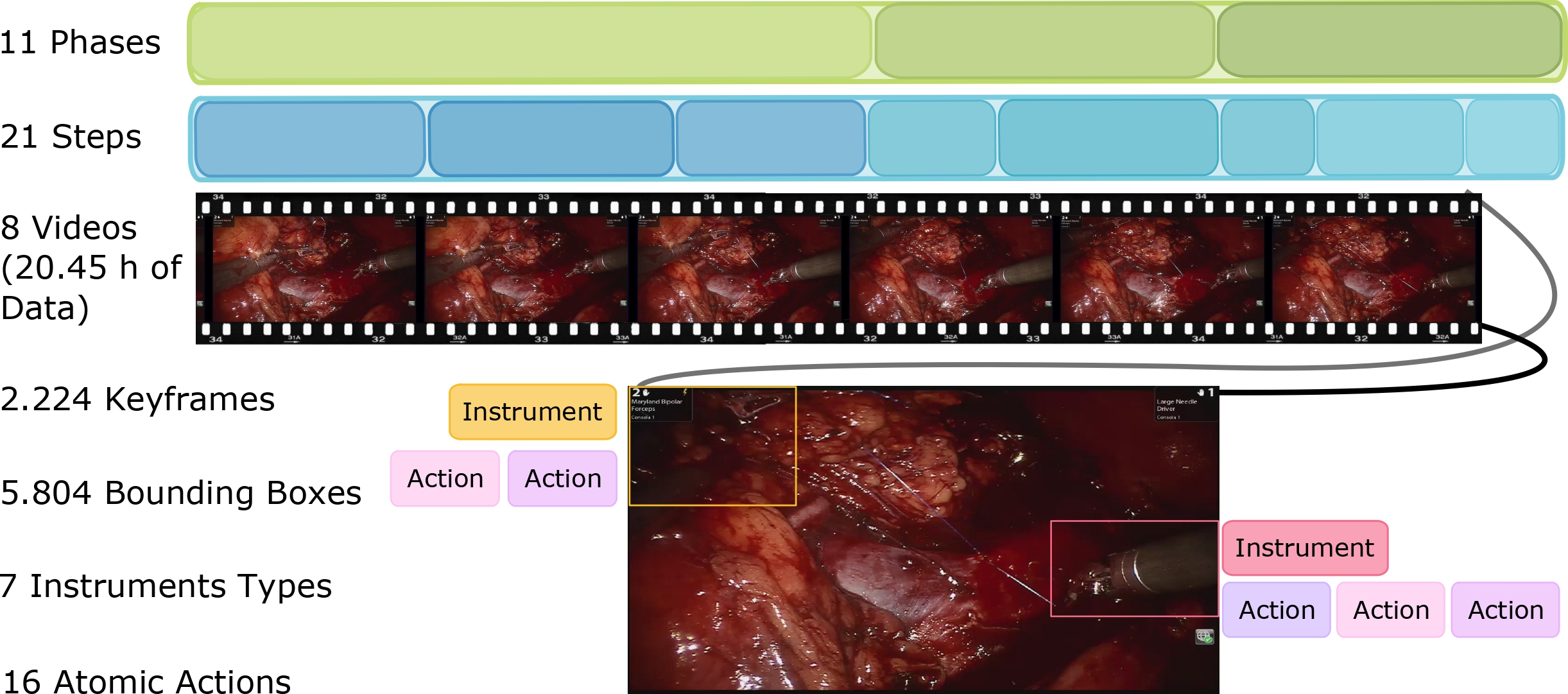
This paper presents the Holistic and Multi-Granular Surgical Scene Understanding of Prostatectomies (GraSP) dataset, a curated benchmark that models surgical scene understanding as a hierarchy of complementary tasks with varying levels of granularity. Our approach enables a multi-level comprehension of surgical activities, encompassing long-term tasks such as surgical phases and steps recognition and short-term tasks including surgical instrument segmentation and atomic visual actions detection. To exploit our proposed benchmark, we introduce the Transformers for Actions, Phases, Steps, and Instrument Segmentation (TAPIS) model, a general architecture that combines a global video feature extractor with localized region proposals from an instrument segmentation model to tackle the multi-granularity of our benchmark. Through extensive experimentation, we demonstrate the impact of including segmentation annotations in short-term recognition tasks, highlight the varying granularity requirements of each task, and establish TAPIS's superiority over previously proposed baselines and conventional CNN-based models. Additionally, we validate the robustness of our method across multiple public benchmarks, confirming the reliability and applicability of our dataset. This work represents a significant step forward in Endoscopic Vision, offering a novel and comprehensive framework for future research towards a holistic understanding of surgical procedures.
PDF Abstract

 MS COCO
MS COCO
 ActivityNet
ActivityNet
 JIGSAWS
JIGSAWS
 CholecT50
CholecT50
 PSI-AVA
PSI-AVA
 MISAW
MISAW
 ESAD
ESAD
 CholecT40
CholecT40
