Perseus: Characterizing Performance and Cost of Multi-Tenant Serving for CNN Models
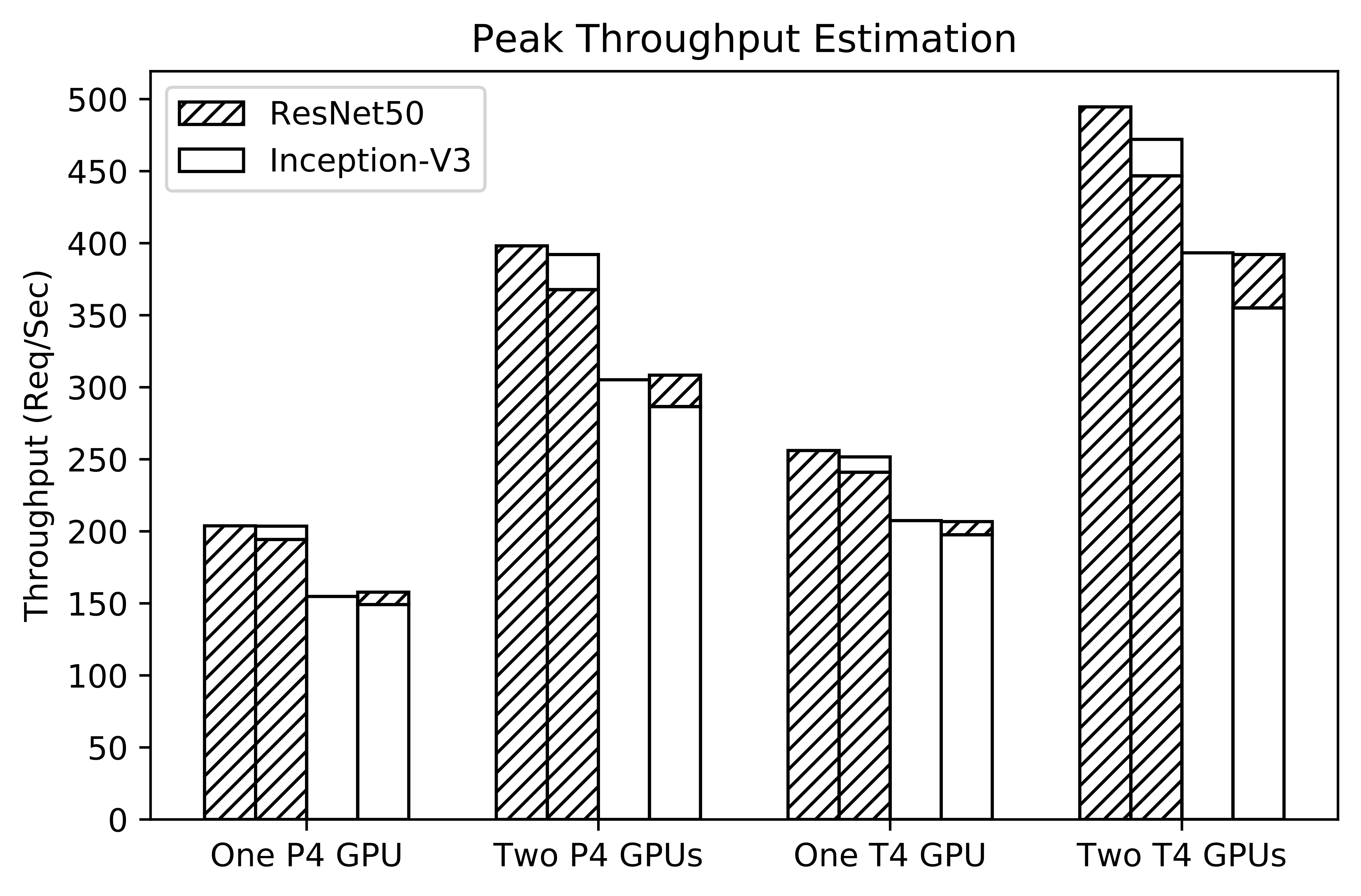
Deep learning models are increasingly used for end-user applications, supporting both novel features such as facial recognition, and traditional features, e.g. web search. To accommodate high inference throughput, it is common to host a single pre-trained Convolutional Neural Network (CNN) in dedicated cloud-based servers with hardware accelerators such as Graphics Processing Units (GPUs). However, GPUs can be orders of magnitude more expensive than traditional Central Processing Unit (CPU) servers. These resources could also be under-utilized facing dynamic workloads, which may result in inflated serving costs. One potential way to alleviate this problem is by allowing hosted models to share the underlying resources, which we refer to as multi-tenant inference serving. One of the key challenges is maximizing the resource efficiency for multi-tenant serving given hardware with diverse characteristics, models with unique response time Service Level Agreement (SLA), and dynamic inference workloads. In this paper, we present Perseus, a measurement framework that provides the basis for understanding the performance and cost trade-offs of multi-tenant model serving. We implemented Perseus in Python atop a popular cloud inference server called Nvidia TensorRT Inference Server. Leveraging Perseus, we evaluated the inference throughput and cost for serving various models and demonstrated that multi-tenant model serving led to up to 12% cost reduction.
PDF Abstract