PCA-Bench: Evaluating Multimodal Large Language Models in Perception-Cognition-Action Chain
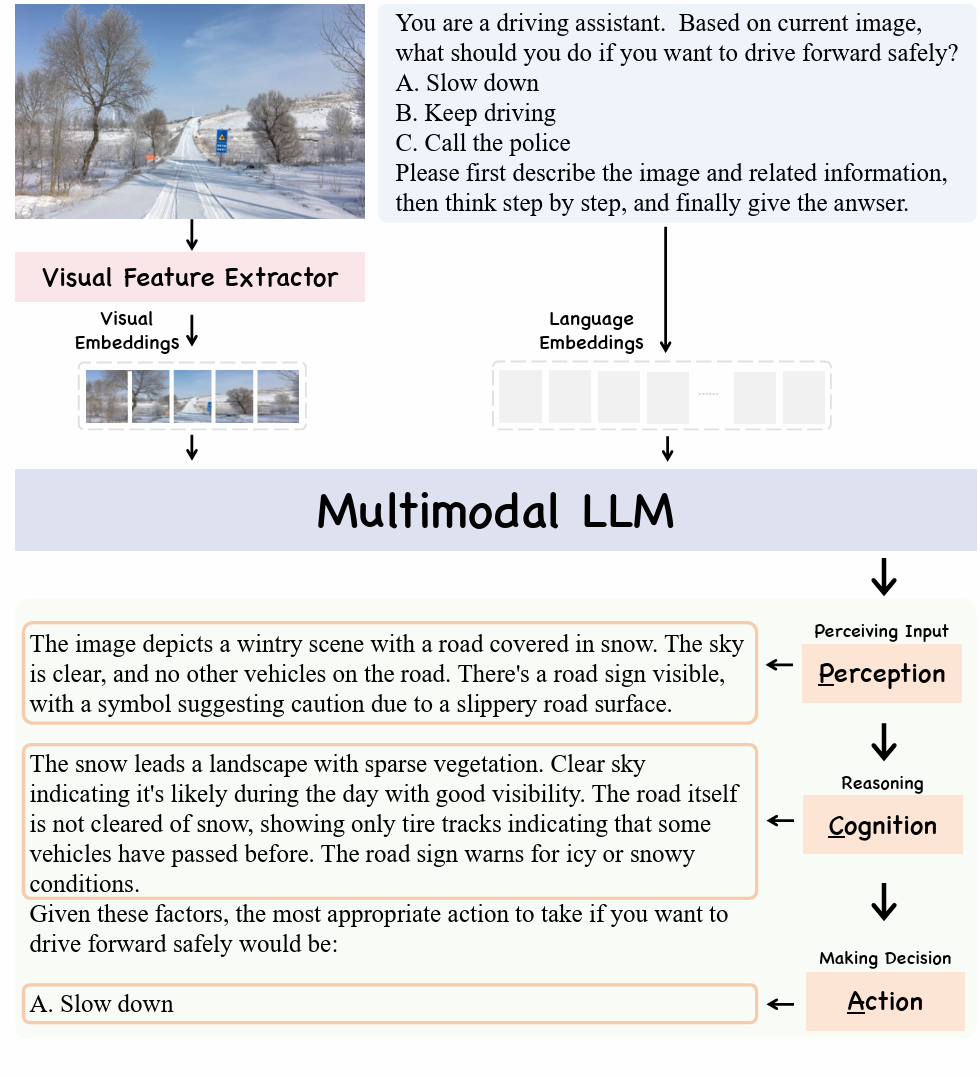
We present PCA-Bench, a multimodal decision-making benchmark for evaluating the integrated capabilities of Multimodal Large Language Models (MLLMs). Departing from previous benchmarks focusing on simplistic tasks and individual model capability, PCA-Bench introduces three complex scenarios: autonomous driving, domestic robotics, and open-world games. Given task instructions and diverse contexts, the model is required to seamlessly integrate multiple capabilities of Perception, Cognition, and Action in a reasoning chain to make accurate decisions. Moreover, PCA-Bench features error localization capabilities, scrutinizing model inaccuracies in areas such as perception, knowledge, or reasoning. This enhances the reliability of deploying MLLMs. To balance accuracy and efficiency in evaluation, we propose PCA-Eval, an automatic evaluation protocol, and assess 10 prevalent MLLMs. The results reveal significant performance disparities between open-source models and powerful proprietary models like GPT-4 Vision. To address this, we introduce Embodied-Instruction-Evolution (EIE), an automatic framework for synthesizing instruction tuning examples in multimodal embodied environments. EIE generates 7,510 training examples in PCA-Bench and enhances the performance of open-source MLLMs, occasionally surpassing GPT-4 Vision (+3\% in decision accuracy), thereby validating the effectiveness of EIE. Our findings suggest that robust MLLMs like GPT4-Vision show promise for decision-making in embodied agents, opening new avenues for MLLM research.
PDF Abstract

 ALFRED
ALFRED
