Paying more attention to snapshots of Iterative Pruning: Improving Model Compression via Ensemble Distillation
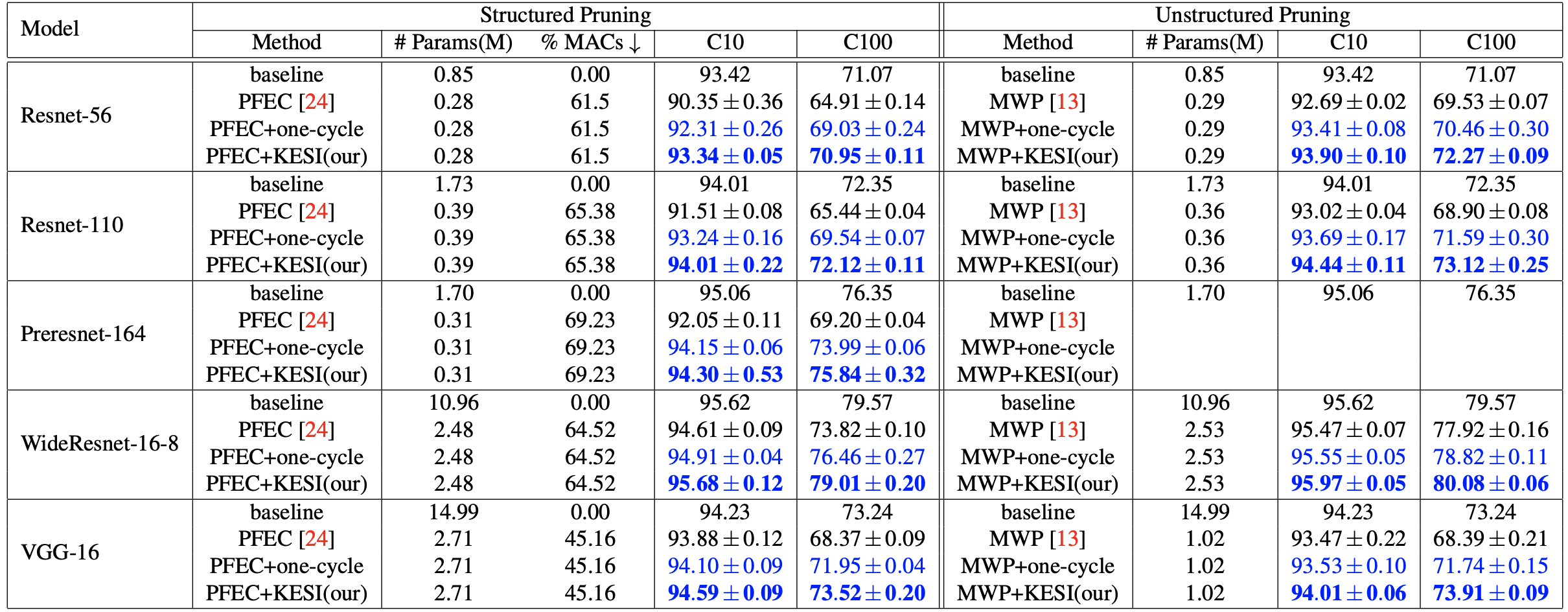
Network pruning is one of the most dominant methods for reducing the heavy inference cost of deep neural networks. Existing methods often iteratively prune networks to attain high compression ratio without incurring significant loss in performance. However, we argue that conventional methods for retraining pruned networks (i.e., using small, fixed learning rate) are inadequate as they completely ignore the benefits from snapshots of iterative pruning. In this work, we show that strong ensembles can be constructed from snapshots of iterative pruning, which achieve competitive performance and vary in network structure. Furthermore, we present simple, general and effective pipeline that generates strong ensembles of networks during pruning with large learning rate restarting, and utilizes knowledge distillation with those ensembles to improve the predictive power of compact models. In standard image classification benchmarks such as CIFAR and Tiny-Imagenet, we advance state-of-the-art pruning ratio of structured pruning by integrating simple l1-norm filters pruning into our pipeline. Specifically, we reduce 75-80% of total parameters and 65-70% MACs of numerous variants of ResNet architectures while having comparable or better performance than that of original networks. Code associate with this paper is made publicly available at https://github.com/lehduong/kesi.
PDF Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
