Partially Synthetic Data for Recommender Systems: Prediction Performance and Preference Hiding
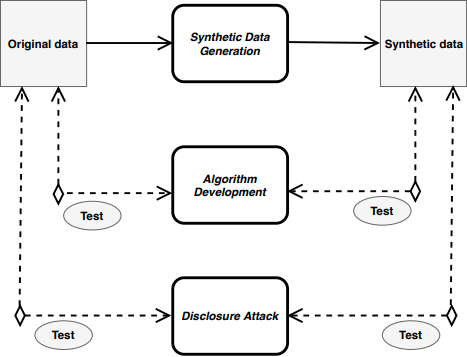
This paper demonstrates the potential of statistical disclosure control for protecting the data used to train recommender systems. Specifically, we use a synthetic data generation approach to hide specific information in the user-item matrix. We apply a transformation to the original data that changes some values, but leaves others the same. The result is a partially synthetic data set that can be used for recommendation but contains less specific information about individual user preferences. Synthetic data has the potential to be useful for companies, who are interested in releasing data to allow outside parties to develop new recommender algorithms, i.e., in the case of a recommender system challenge, and also reducing the risks associated with data misappropriation. Our experiments run a set of recommender system algorithms on our partially synthetic data sets as well as on the original data. The results show that the relative performance of the algorithms on the partially synthetic data reflects the relative performance on the original data. Further analysis demonstrates that properties of the original data are preserved under synthesis, but that for certain examples of attributes accessible in the original data are hidden in the synthesized data.
PDF Abstract

