Parameter-Efficient Long-Tailed Recognition
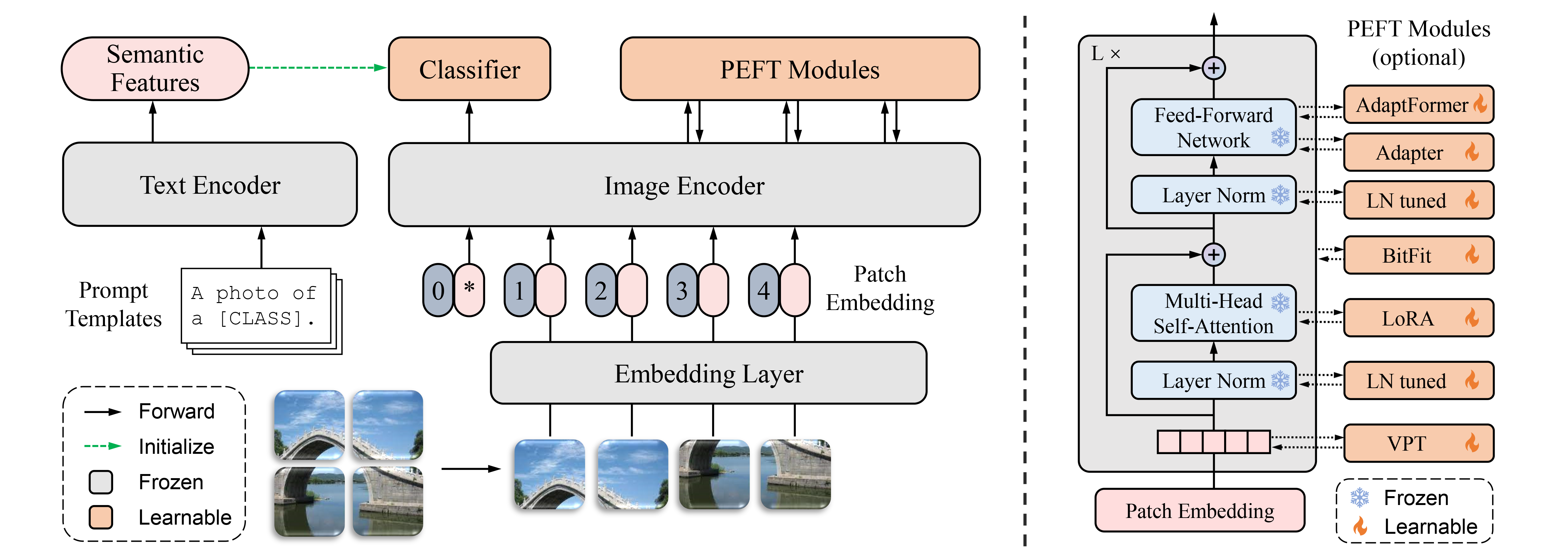
The "pre-training and fine-tuning" paradigm in addressing long-tailed recognition tasks has sparked significant interest since the emergence of large vision-language models like the contrastive language-image pre-training (CLIP). While previous studies have shown promise in adapting pre-trained models for these tasks, they often undesirably require extensive training epochs or additional training data to maintain good performance. In this paper, we propose PEL, a fine-tuning method that can effectively adapt pre-trained models to long-tailed recognition tasks in fewer than 20 epochs without the need for extra data. We first empirically find that commonly used fine-tuning methods, such as full fine-tuning and classifier fine-tuning, suffer from overfitting, resulting in performance deterioration on tail classes. To mitigate this issue, PEL introduces a small number of task-specific parameters by adopting the design of any existing parameter-efficient fine-tuning method. Additionally, to expedite convergence, PEL presents a novel semantic-aware classifier initialization technique derived from the CLIP textual encoder without adding any computational overhead. Our experimental results on four long-tailed datasets demonstrate that PEL consistently outperforms previous state-of-the-art approaches. The source code is available at https://github.com/shijxcs/PEL.
PDF AbstractCode




 CIFAR-100
CIFAR-100
 iNaturalist
iNaturalist
 Places365
Places365
Results from the Paper
 Ranked #1 on
Long-tail Learning
on CIFAR-100-LT (ρ=10)
(using extra training data)
Ranked #1 on
Long-tail Learning
on CIFAR-100-LT (ρ=10)
(using extra training data)
